Basic Model Walkthrough
Mark Grabowski
2025-10-18
Basic_Models-Examples.Rmd
########################################################################################################
#For execution on a local, multicore CPU with excess RAM we recommend calling
#options(mc.cores = parallel::detectCores())
options(mc.cores = 2) #2 For R package checks - use line above on your own machine
rstan::rstan_options(auto_write = TRUE)
dotR <- file.path(Sys.getenv("HOME"), ".R")
if (!file.exists(dotR)) dir.create(dotR)
M <- file.path(dotR, "Makevars")
if (!file.exists(M)) file.create(M)
arch <- ifelse(R.version$arch == "aarch64", "arm64", "x86_64")
cat(paste("\nCXX14FLAGS += -O3 -mtune=native -arch", arch, "-ftemplate-depth-256"),
file = M, sep = "\n", append = FALSE)Here I walk you through the basic models of Blouch. By basic I mean either the direct effect model, adaptive model, or model with a combination of both types of predictors. This article is an abbreviated versions of the Simulation Example article - most of the steps of analysis will be the same and are not repeated here. Note that the Stan runs are also too few iterations and use only 1 chain and 1 core.
Direct effect model
Blouch implements the model of constrained evolution (Hansen & Bartoszek, 2012) known as the direct effect model, previously implemented in Grabowski et al. (2016; see also Grabowski et al. 2023), which can be used to test for allometric constraints.
Create Phylogeny
The Blouch package includes the primate phylogeny from the 10KTrees Project (Arnold et al. 2010), which is used for various simulations and comes from https://10ktrees.nunn-lab.org/. This is Version 3 of their primate phylogeny with 301 tips. Here we randomly reduce the tip number to 100 for a more manageable tree using functions from the ape R package (Paradis et al. 2004)
########################################################################################################
#Create phylogeny
########################################################################################################
N<-50 #Number of species
set.seed(10) #Set seed to get same random species each time
phy <- ape::keep.tip(tree.10K,sample(tree.10K$tip.label)[1:N])
phy<-ape::multi2di(phy)
l.tree<-max(ape::branching.times(phy)) ## rescale tree to height 1
phy$edge.length<-phy$edge.length/l.tree
tip.label<-phy$tip.labelSet true/known parameter values
Next we set our true/known parameter values. These are for the half-life (hl), and stationary variance (vy), which in our simulation we translate to (a) and (sigma2_y). We set the ancestral value at the root (vX0) to 0, and the instantaneous variance of the BM process (Sxx) to to 10.
########################################################################################################
#Direct Effect Model
########################################################################################################
#Setup parameters
Z_direct<-1 #Number of traits
hl<-0.1 #half life
a<-log(2)/hl
vy<-0.01 #0.25,0.5 - testing options
sigma2_y<-vy*(2*(log(2)/hl));
vX0<-0 #value for ancestral state at the root node.
vY0 <- 0 #value for ancestral state at the root node.
Sxx<-10 #Variance of BM processCalculate V and simulate X data
We will use the Blouch helper R function calc_direct_V to calculate the direct effect variance/covariance matrix, and the fastBM function from phytools (Revell, 2011) to simulate the X variable following a BM process.
V<-calc_direct_V(phy,sigma2_y,a) #Calculate V - variance/covariance matrix
X<-phytools::fastBM(phy,a=vX0,sig2=Sxx,internal=FALSE) #Simulate X BM variable on tree, with scaling 10
phytools::phenogram(phy,X,spread.labels=TRUE,spread.cost=c(1,0)) #Plot X data
#> Optimizing the positions of the tip labels...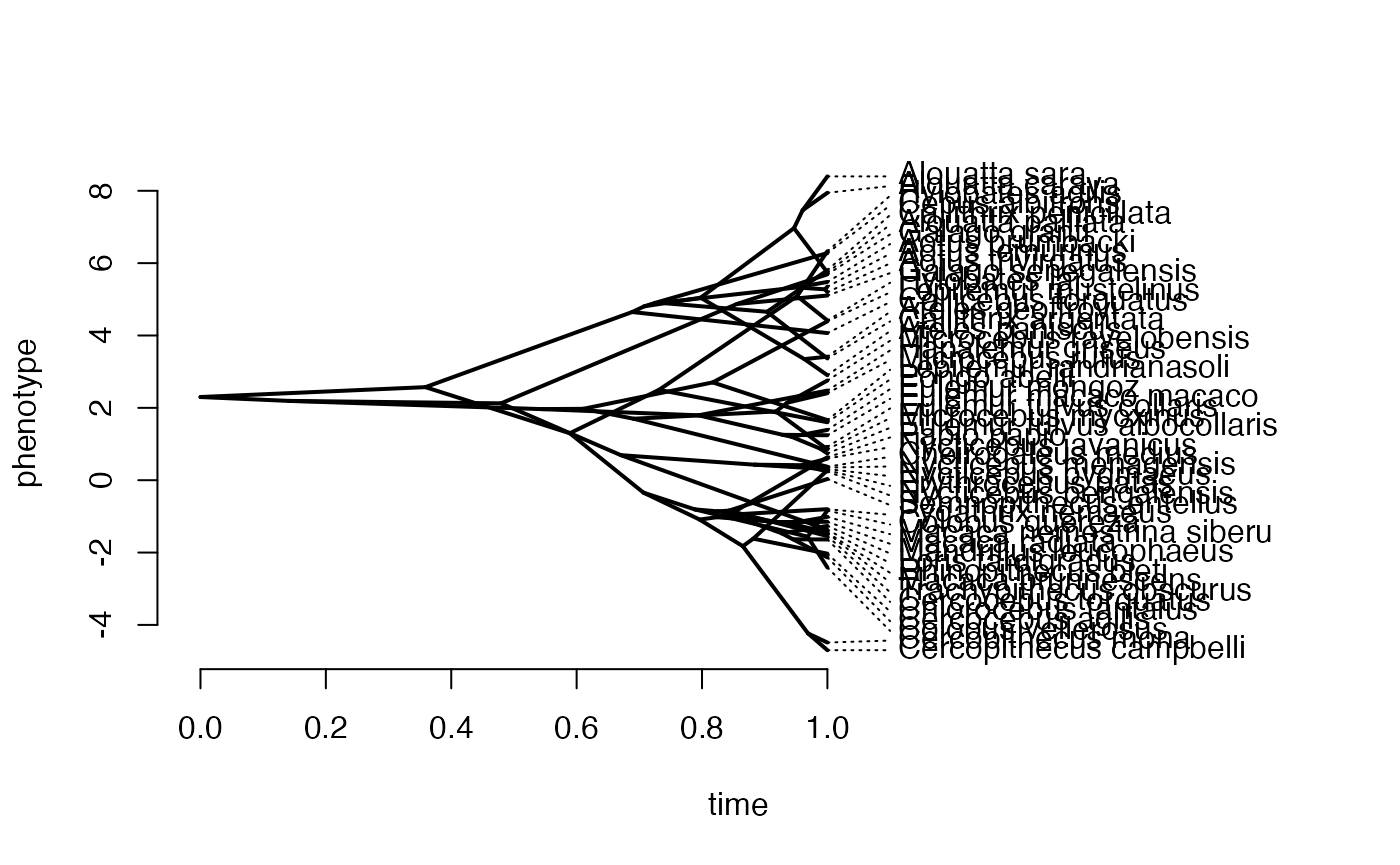
Simulate Y data
Next we set the intercept and slope parameters, and simulate mu before using it and V to simulate Y. Finally we make a quick plot of the results. We will set the intercept (alpha term) to 2 and the slope to 0.25.
optima<-2 #Intecept
beta<-0.25 #Slope
mu<-optima+X*beta #Simulate mu for Y
Y<-MASS::mvrnorm(n=1,mu,V) #Simulate direct effect Y trait
df<-data.frame(Y=Y,X=X)
names(df)<-c("Y","X")
ggplot2::ggplot(data=df,ggplot2::aes(x=X,y=Y))+
ggplot2::geom_point()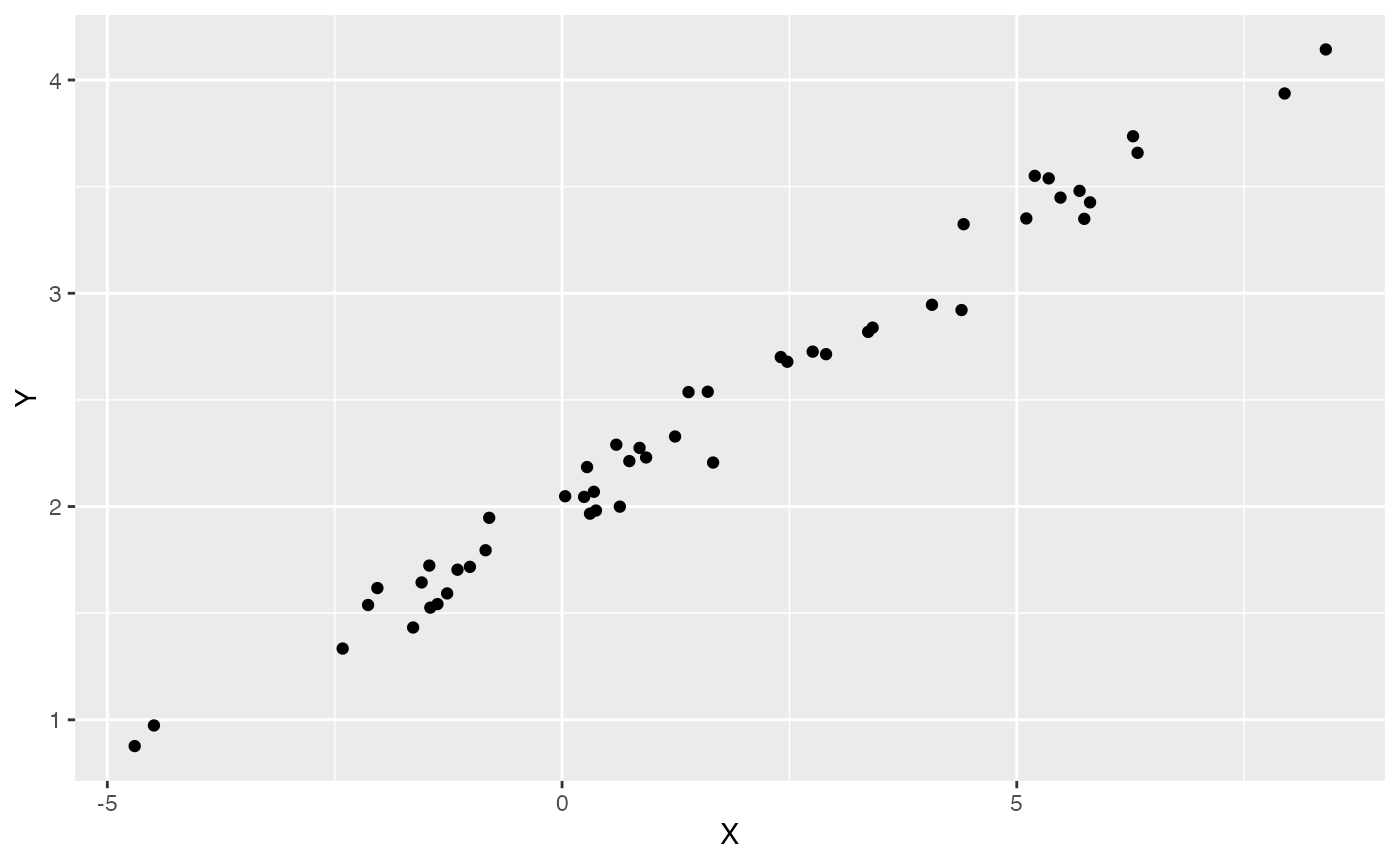
summary(lm(Y~X,df))
#>
#> Call:
#> lm(formula = Y ~ X, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.230186 -0.067083 0.004429 0.073317 0.210824
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 2.012457 0.016954 118.70 <2e-16 ***
#> X 0.255341 0.004832 52.84 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.1065 on 48 degrees of freedom
#> Multiple R-squared: 0.9831, Adjusted R-squared: 0.9827
#> F-statistic: 2792 on 1 and 48 DF, p-value: < 2.2e-16Simulating measurement error
Next we will simulate measurement error - we will use a standard deviation of measurement error of 0.01, which we will provide to Blouch as a vector (X_error and Y_error), and use the rnorm function to add error to our X and Y variables. In other words, we are telling Blouch that the estimated error on X and Y is 0.01, and providing it with X and Y variables that are offset by a random amount of error with this standard deviation.
Combine data and tree
Next we will use the treeplyr package (Uyeda and Harmon, 2014) make.treedata function to combine the data and tree based on the taxa names. See https://github.com/uyedaj/treeplyr for more on this package.
############################################################################################################
#Make trdata file
trait.data<-data.frame(cbind(Y_with_error,Y_error,X_with_error,X_error))
trdata<-treeplyr::make.treedata(phy,trait.data)Next we will set the priors for the estimated parameters - for this model this includes the half-life, Vy, optima, and beta. For the latter two parameters we will use the results of the linear model to inform our priors.
Exploring Priors
At this point one would want to explore if the priors are appropriate - do the prior distributions look consistent with what we know about our system? See Grabowski (in press) for more on setting priors.
Half-life Prior plot
hl.sims<-data.frame(rlnorm(n=1000,meanlog=hl.prior[1],sdlog=hl.prior[2]))
names(hl.sims)<-"prior.hl.sims"
hl.prior.plot<-ggplot2::ggplot()+
ggplot2::geom_density(ggplot2::aes(prior.hl.sims,fill="prior.hl.sims"),alpha=0.2,data=hl.sims)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#labs(title="Prior vs. Posterior Distribution ",x="Half-life", y = "Density")+
ggplot2::labs(title="",x="Half-life", y = "Density")+
#scale_fill_manual(labels=c("Posterior","Prior"))+
ggplot2::geom_vline(xintercept=c(hl),linetype=2)+
ggsci::scale_fill_npg(name="",labels=c("Prior"))
hl.prior.plot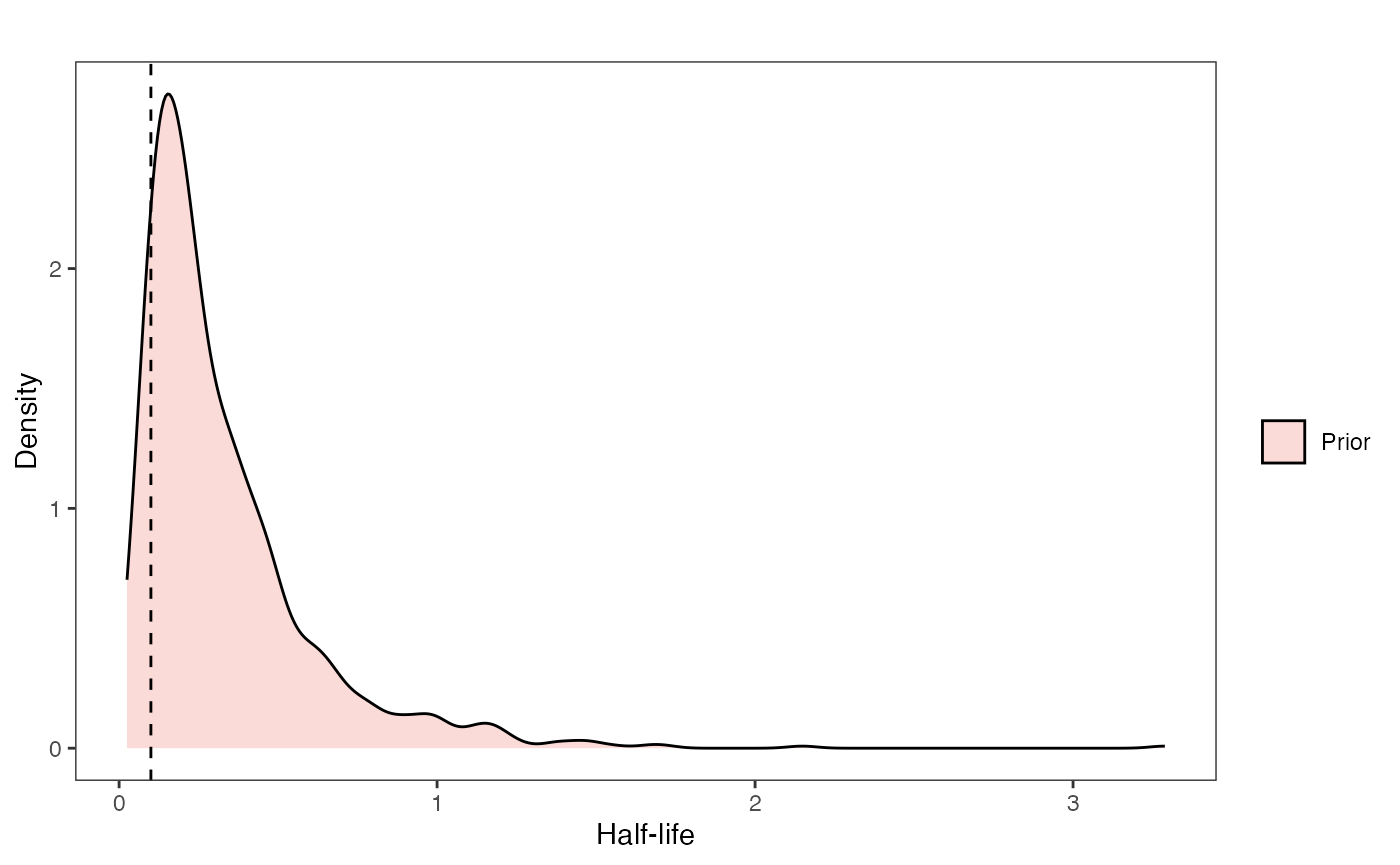
Vy Prior Plot
vy.sims<-rexp(n=1000,rate=vy.prior)
vy.sims<-data.frame(vy.sims)
names(vy.sims)<-"prior.vy.sims"
vy.prior.plot<-ggplot2::ggplot()+
ggplot2::geom_density(ggplot2::aes(prior.vy.sims,fill="prior.vy.sims"),alpha=0.2,data=vy.sims)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#labs(title="Prior vs. Posterior Distribution ",x="vy", y = "Density")+
ggplot2::labs(title="",x="vy", y = "Density")+
ggplot2::geom_vline(xintercept=c(vy),linetype=2)+
#scale_fill_manual(labels=c("Posterior","Prior"))+
ggsci::scale_fill_npg(name="",labels=c("Prior"))
vy.prior.plot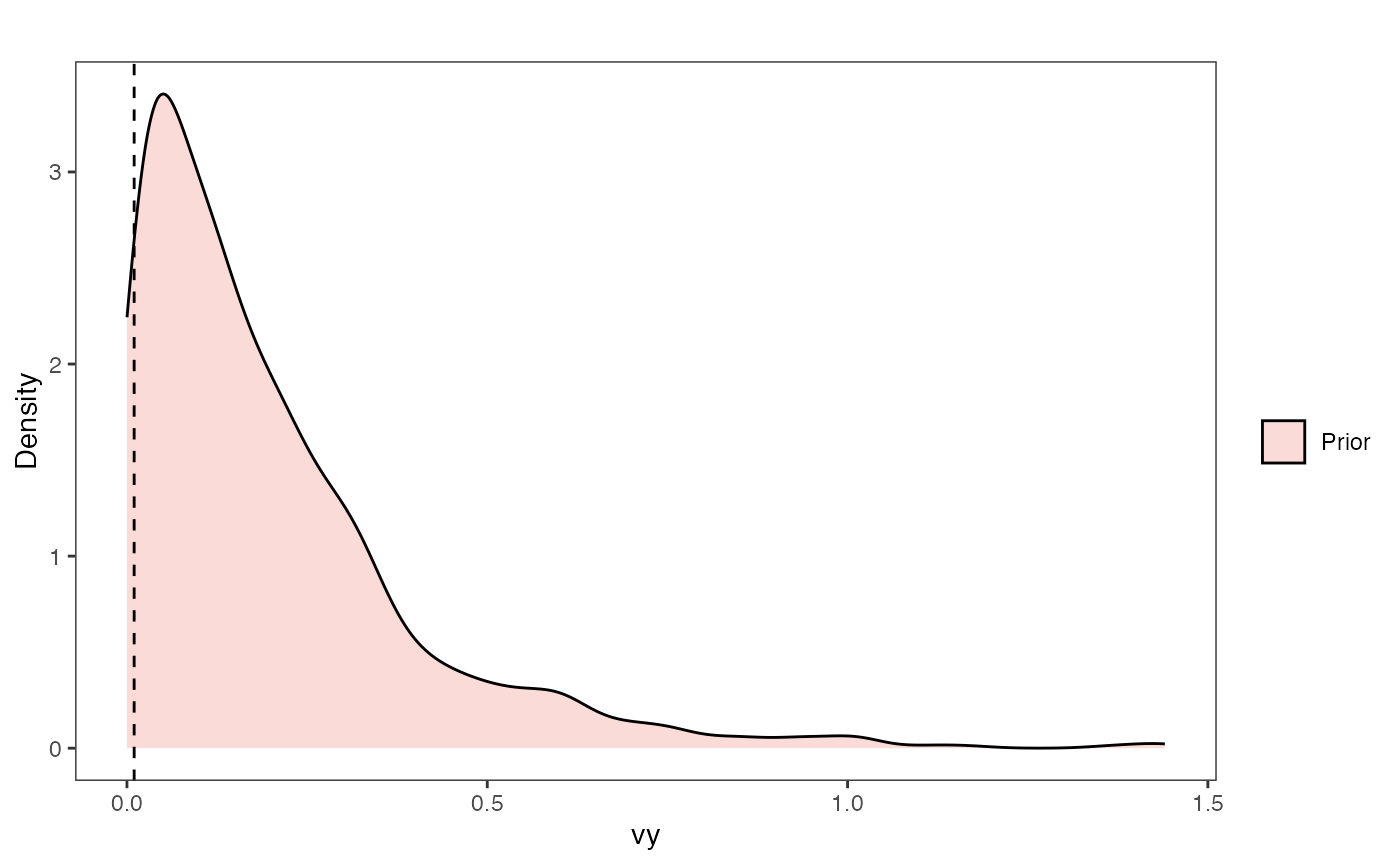
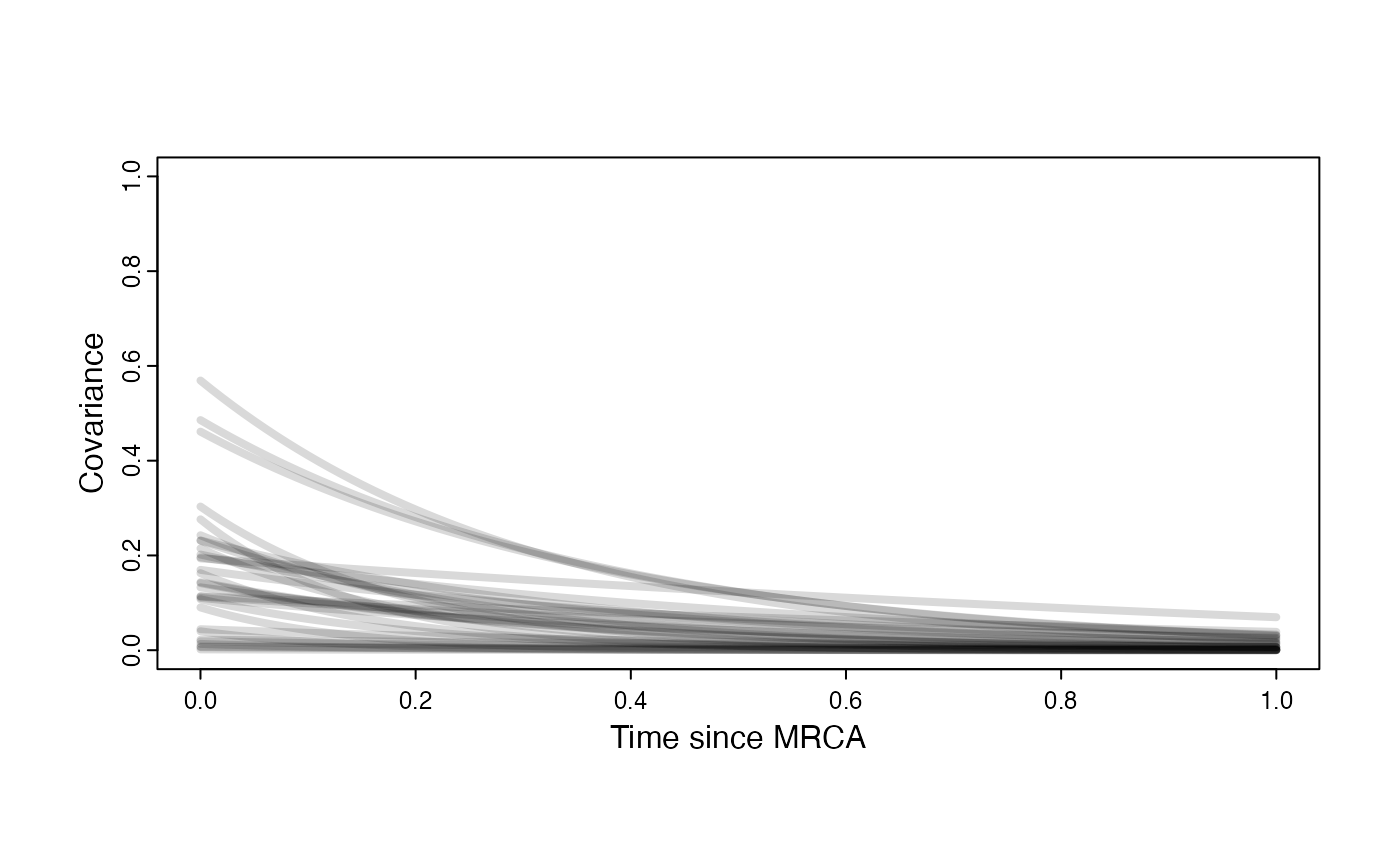
Prior on how shared branch lengths correspond to covariance
a.sims<-log(2)/hl.sims;
sigma2_y.sims<-vy.sims*(2*(log(2)/hl.sims));
#x<-seq(from=0,to=1,by=0.001)
#V.sim<-calc_direct_V(phy,a.sims,sigma2_y.sims)
plot( NULL , xlim=c(0,1) , ylim=c(0,1) , xlab="Time since MRCA" , ylab="Covariance" ,cex.axis=0.75, mgp=c(1.25,0.25,0),tcl=-0.25)
for (i in 1:30){
curve(sigma2_y.sims[i,] /(2 * a.sims[i,]) * ((1 - exp(-2 * a.sims[i,] * (1-(x/2)))) * exp(-a.sims[i,] * x)) , add=TRUE , lwd=4 , col=rethinking::col.alpha(1,0.15))
}
par(mar=c(3,3,0.25,0.25))
covariance.prior.plot <- recordPlot()
dev.off()
#> null device
#> 1
covariance.prior.plotSlope and intercept Prior Plot
optima.sims<-rnorm(100,optima.prior[1],optima.prior[2])
beta.sims<-rnorm(n=100,beta.prior[1],beta.prior[2])
prior.slope.plot<-ggplot2::ggplot()+
ggplot2:: geom_point(data=df,ggplot2::aes(y=Y,x=X))+
ggplot2::geom_abline(intercept=optima.sims,slope=beta.sims,alpha=0.15)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
ggplot2::ylab("Y") + ggplot2::xlab("Direct Effect X")+
ggsci::scale_color_npg()
prior.slope.plot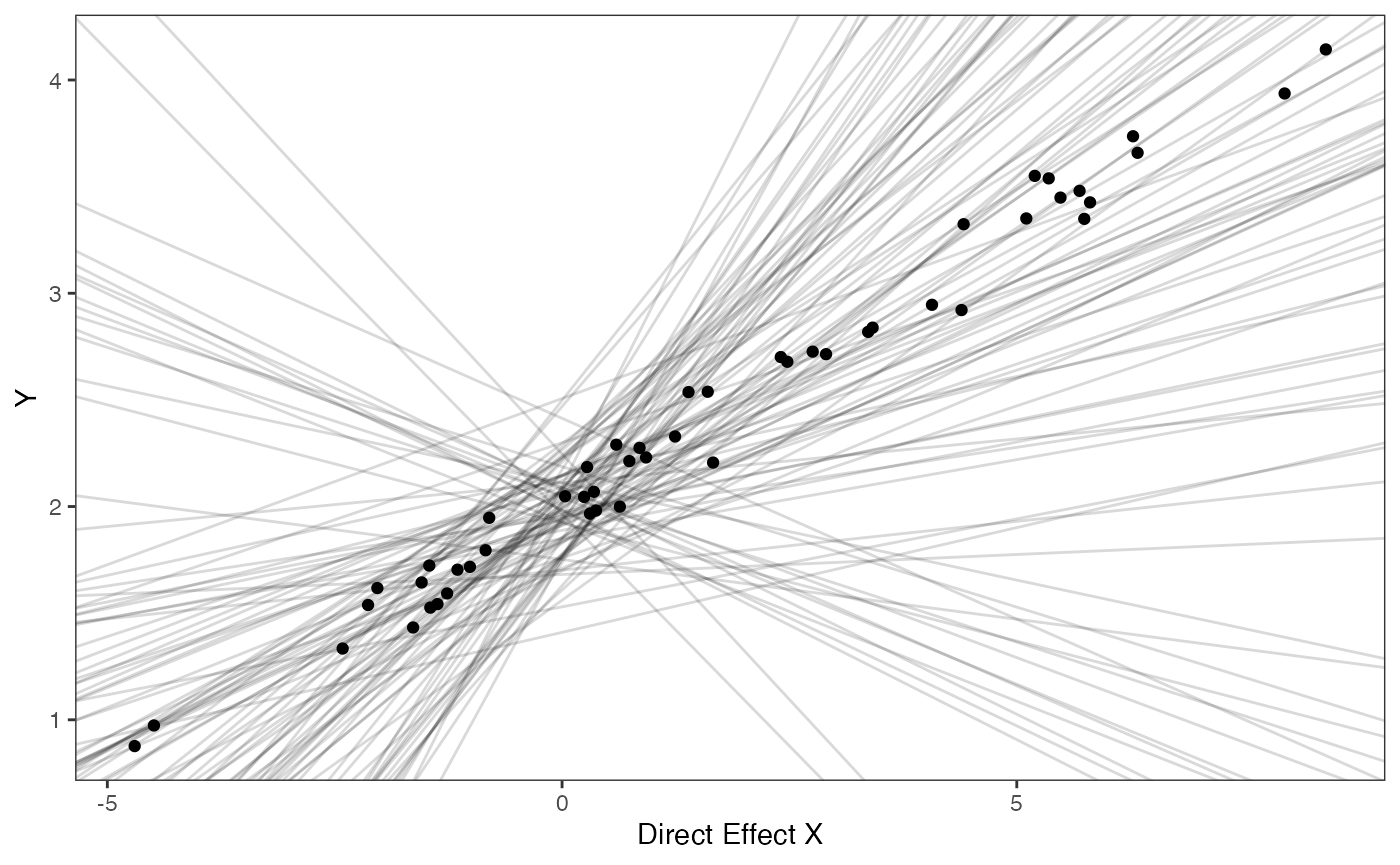
Not for the faint of heart
And here are the lines of Stan code for setting these priors. To change the values to make them appropriate for your own analyses, you just need to change the numbers below. All Stan programs are in the Blouch/inst/stan folder and named according to the model they run. See Table S1 of Grabowski (in press) for more on the models. Remember, your priors should be based on what you know about the biological processes underlying your research question and prior predictive simulations (see McElreath 2020)
#Stan Code
Data setup for Blouch
We will use the helper function blouch.direct.prep to setup the dat file for Stan. Here the name of the column in trdata$dat that contains the response variable is “Y_with_error”, the associated error column name is “Y_error,” the direct effect predictor column is named “X_with_error”, and its associated errors is “X_error”. Finally, we give the helper function the number of predictor traits, 1 here. The last few variables are all the priors for the parameters above.
############################################################################################################
#Test Blouch prep code - direct effect model - blouch.direct.prep()
dat<-blouch.direct.prep(trdata,"Y_with_error","Y_error","X_with_error","X_error", hl.prior,vy.prior,optima.prior,beta.prior)Running models
We will run the direct effect model first. Below are the priors used for this simulation. See Grabowski (in press) for more on setting these priors. To change these values requires you to open the Stan function, in this case blouchOU_direct, and manually edit them. Unfortunately there is no way around this at present, but trust me - it will be worth it.
For example, here are the four most important priors for the model below - these values are explored in Grabowski (in press). Remember, always do prior predictive simulations first - in other words, look at distributions of the values and see if they are actually biologically possible - see the exploring priors step above. Now let’s run the direct effect model blouchOU_direct.
fit.direct<- rstan::sampling(object = blouch:::stanmodels$blouchOU_direct,data = dat,chains = 2,cores=2,iter =2000)
#> Found more than one class "stanfit" in cache; using the first, from namespace 'rstan'
#> Also defined by 'rethinking'
#> Found more than one class "stanfit" in cache; using the first, from namespace 'rstan'
#> Also defined by 'rethinking'Now let’s look at the results
print(fit.direct,pars = c("hl","vy","optima","beta"))
#> Inference for Stan model: blouchOU_direct.
#> 2 chains, each with iter=2000; warmup=1000; thin=1;
#> post-warmup draws per chain=1000, total post-warmup draws=2000.
#>
#> mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
#> hl 0.16 0 0.10 0.05 0.10 0.14 0.20 0.39 1314 1
#> vy 0.02 0 0.01 0.01 0.01 0.02 0.02 0.03 1299 1
#> optima 2.00 0 0.03 1.93 1.98 2.00 2.02 2.06 2277 1
#> beta[1] 0.26 0 0.01 0.24 0.25 0.26 0.26 0.27 2792 1
#>
#> Samples were drawn using NUTS(diag_e) at Sat Oct 18 11:55:44 2025.
#> For each parameter, n_eff is a crude measure of effective sample size,
#> and Rhat is the potential scale reduction factor on split chains (at
#> convergence, Rhat=1).
post<-rstan::extract(fit.direct) #Extract posterior distributionNow lets look at the prior vs. posterior plots for the parameters Half-life plot
hl.post<-data.frame(post$hl)
names(hl.post)<-"post.hl.sims"
hl.plot<-ggplot2::ggplot()+
ggplot2::geom_density(ggplot2::aes(prior.hl.sims,fill="prior.hl.sims"),alpha=0.2,data=hl.sims)+
ggplot2::geom_density(ggplot2::aes(post.hl.sims,fill="post.hl.sims"),alpha=0.2,data=hl.post)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#labs(title="Prior vs. Posterior Distribution ",x="Half-life", y = "Density")+
ggplot2::labs(title="",x="Half-life", y = "Density")+
#scale_fill_manual(labels=c("Posterior","Prior"))+
ggplot2::geom_vline(xintercept=c(hl),linetype=2)+
ggsci::scale_fill_npg(name="",labels=c("Posterior","Prior"))
hl.plot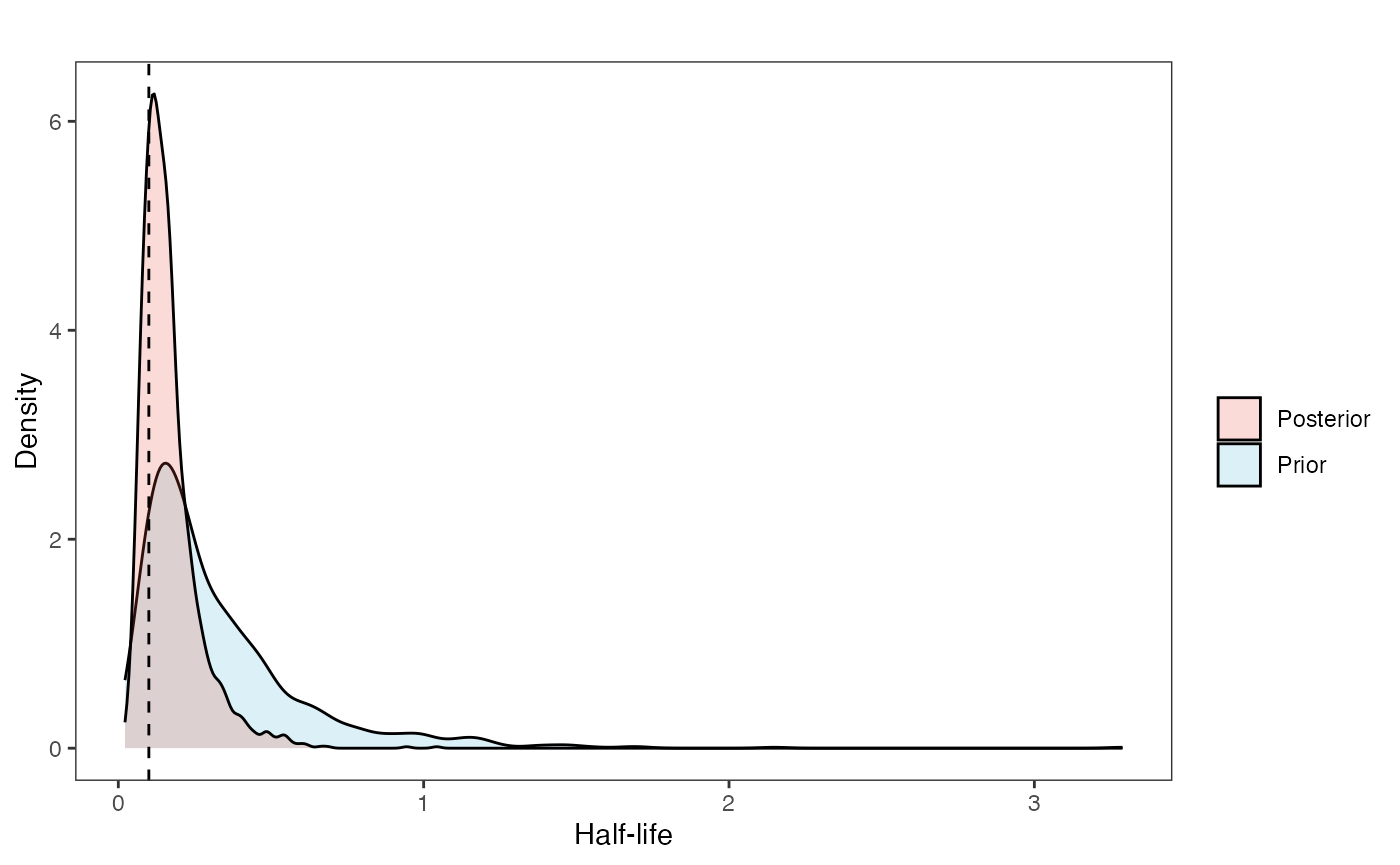
Vy Prior vs. posterior plot
vy.post<-data.frame(post$vy)
names(vy.post)<-"post.vy.sims"
vy.plot<-ggplot2::ggplot()+
ggplot2::geom_density(ggplot2::aes(prior.vy.sims,fill="prior.vy.sims"),alpha=0.2,data=vy.sims)+
ggplot2::geom_density(ggplot2::aes(post.vy.sims,fill="post.vy.sims"),alpha=0.2,data=vy.post)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#labs(title="Prior vs. Posterior Distribution ",x="vy", y = "Density")+
ggplot2::labs(title="",x="vy", y = "Density")+
ggplot2::geom_vline(xintercept=c(vy),linetype=2)+
#scale_fill_manual(labels=c("Posterior","Prior"))+
ggsci::scale_fill_npg(name="",labels=c("Posterior","Prior"))
vy.plot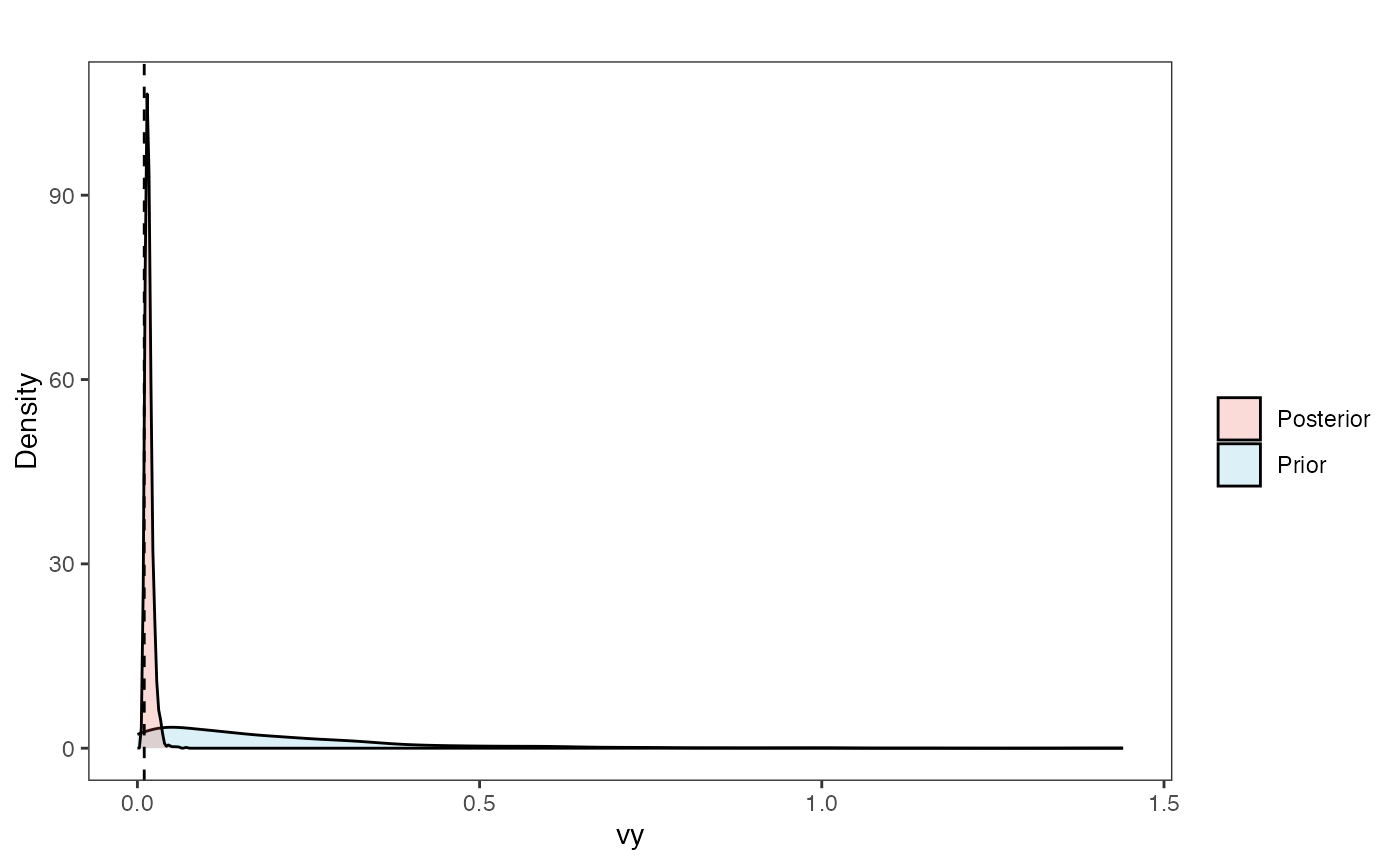
Prior versus posterior on how shared branch lengths correspond to covariance
plot( NULL , xlim=c(0,1) , ylim=c(0,1) , xlab="Time since MRCA" , ylab="Covariance" ,cex.axis=0.75, mgp=c(1.25,0.25,0),tcl=-0.25)
for (i in 1:30){
curve(sigma2_y.sims[i,] /(2 * a.sims[i,]) * ((1 - exp(-2 * a.sims[i,] * (1-(x/2)))) * exp(-a.sims[i,] * x)) , add=TRUE , lwd=4 , col=rethinking::col.alpha(1,0.15))
}
for (i in 1:30){
curve(post$sigma2_y[i] /(2 * post$a[i]) * ((1 - exp(-2 * post$a[i] * (1-(x/2)))) * exp(-post$a[i] * x)) , add=TRUE , lwd=4 , col=rethinking::col.alpha(2,0.5))
}
par(mar=c(3,3,0.25,0.25))
covariance.plot <- recordPlot()
dev.off()
#> null device
#> 1
covariance.plotPrior vs. Posterior Plot for Regression
optima.sims<-rnorm(100,optima.prior[1],optima.prior[2])
beta.sims<-rnorm(n=100,beta.prior[1],beta.prior[2])
optima.post<-data.frame(post$optima)
names(optima.post)<-"post.optima"
beta.post<-data.frame(post$beta)
names(beta.post)<-"post.beta"
mu.link<-function(x.seq){optima.post+x.seq*beta.post}
x.seq <- seq(from=min(X), to=max(X) , length.out=100)
mu <- sapply(x.seq , mu.link )
mu.mean <-lapply( mu , mean )
mu.mean<-data.frame(as.numeric(mu.mean))
names(mu.mean)<-"mu.mean"
mu.CI <- lapply( mu , rethinking::PI , prob=0.89 )
mu.CI<-data.frame(t(data.frame(mu.CI)),x.seq)
names(mu.CI)<-c("min.5.5","max.94.5","x.seq")
#df<-data.frame(Y=stan_sim_data$Y,X=stan_sim_data$direct_cov)
df<-data.frame(Y=Y,X=X)
names(df)<-c("Y","X")
df2<-data.frame(x.seq,mu.mean)
#slope.prior.plot<-ggplot(data=reg.trdata$dat,aes(y=Sim1,x=X))+
slope.plot<-ggplot2::ggplot()+
ggplot2::geom_point(data=df,ggplot2::aes(y=Y,x=X))+
ggplot2::geom_abline(intercept=optima.sims,slope=beta.sims,alpha=0.15)+
ggplot2::geom_abline(intercept=optima,slope=beta,alpha=0.5,linetype=2)+
ggplot2::geom_line(data=df2,ggplot2::aes(x=x.seq,y=mu.mean),linetype=1)+
ggplot2::geom_ribbon(data=mu.CI,ggplot2::aes(x=x.seq,ymin=min.5.5,ymax=max.94.5),linetype=2,alpha=0.25)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#ggtitle("Prior vs. Posterior for Intercept and Slope")+
ggplot2::ylab("Y") + ggplot2::xlab("Direct Effect X")+
ggsci::scale_color_npg()
slope.plot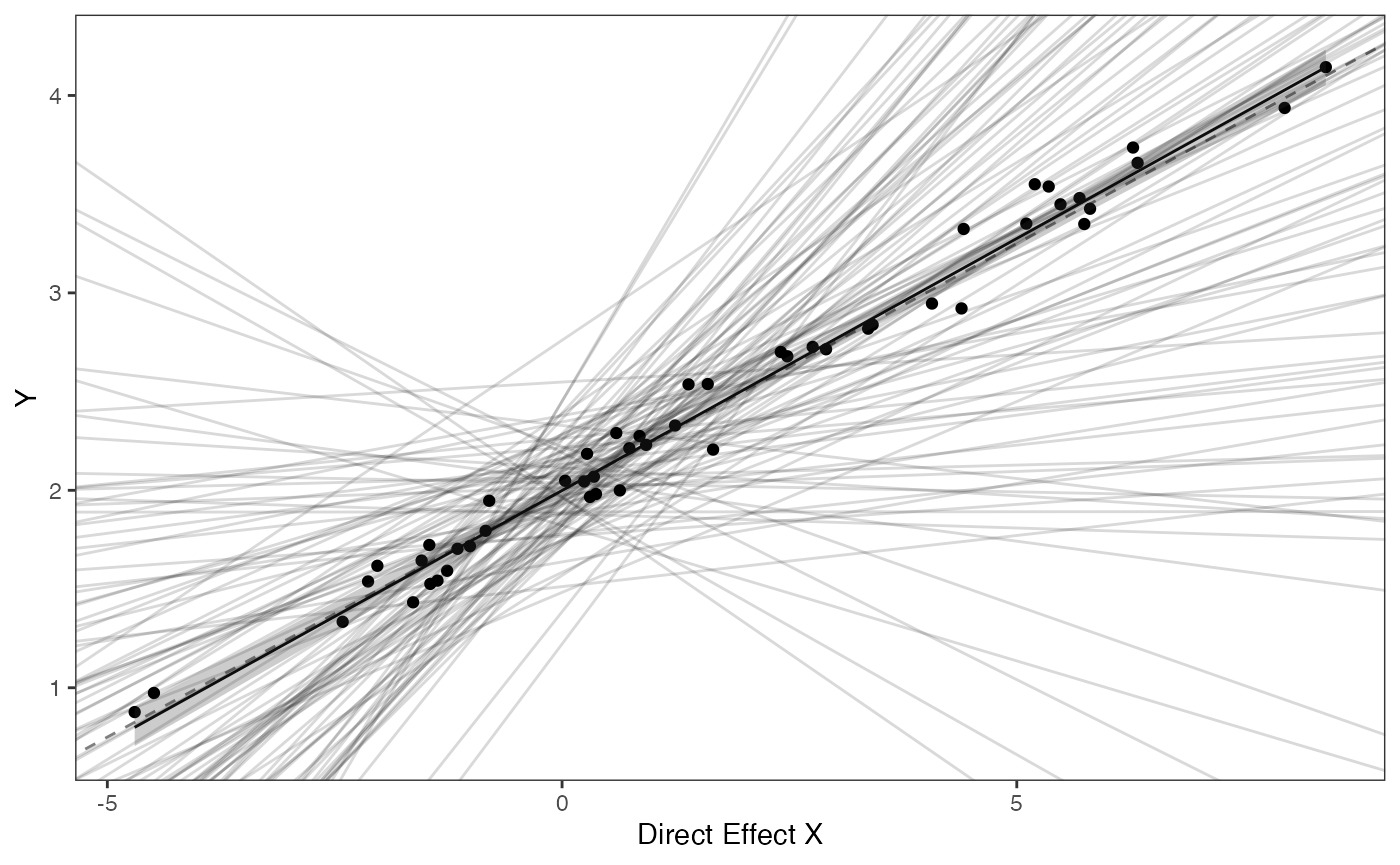
Adaptive Model
Blouch also implements the model of adaptive evolution introduced by Hansen et al. (2008). Here the response variable evolves according to an Ornstein-Uhlenbeck process towards an optimal state that is modeled as a function of the predictor variable. Most of these steps below are similar to those above for the direct effect model so I will not go into them fully.
Again, we will create a phylogeny by randomly sampling from the 10K Trees phylogeny.
########################################################################################################
#Create phylogeny
########################################################################################################
N<-50 #Number of species
set.seed(10) #Set seed to get same random species each time
phy <- ape::keep.tip(tree.10K,sample(tree.10K$tip.label)[1:N])
phy<-ape::multi2di(phy)
l.tree<-max(ape::branching.times(phy)) ## rescale tree to height 1
phy$edge.length<-phy$edge.length/l.tree
tip.label<-phy$tip.labelSet true/known parameter values
First we will simulate X and Y data using a generative model for the adaptive model.
We will set our true/known parameter values. These are for the half-life (hl), and stationary variance (vy), which in our simulation we translate to (a) and (sigma2_y). We set the ancestral value at the root (vX0) to 0, and the instantaneous variance of the BM process (Sxx) to to 10.
########################################################################################################
#Adaptive Model
########################################################################################################
#Setup parameters
Z_adaptive<-1 #Number of traits
hl<-0.1
a<-log(2)/hl
vy<-0.1 #0.25,0.5 - testing options
sigma2_y<-vy*(2*(log(2)/hl));
vX0<-0 #value for ancestral state at the root node.
vY0<-0#value for ancestral state at the root node.We will use the the fastBM function from phytools (Revell, 2011) to simulate the X variable following a BM process. Because this is a simulation we are setting the instantaneous variance of the BM process (sigma2_x) to 1, which needs to be in matrix format. Normally Blouch estimates this as part of the blouch.adapt.prep helper function.
sigma2_x<-matrix(1,1,1) #Variance of BM Process
X<-phytools::fastBM(phy,a=vX0,sig2=sigma2_x[1,1],internal=FALSE) #Simulate X BM variable on tree, with scaling 10
phytools::phenogram(phy,X,spread.labels=TRUE,spread.cost=c(1,0)) #Plot X data
#> Optimizing the positions of the tip labels...
Calculate V and simulate Y data
We will set the intercept (alpha) to 2 and the slope to 0.25. We will use the Blouch helper functions calc_adaptive_dmX to calculate the design matrix and calc_adaptive_V to calculate the variance/covariance matrix.
Then we will simulate mu before using it and V to simulate Y. Finally we make a quick plot of the results.
optima<-2 #Intecept
beta<-0.25 #Slope
dmX<-calc_adaptive_dmX(phy,a,X) #Calculate the design matrix
V<-calc_adaptive_V(phy,a, sigma2_y, beta, sigma2_x, Z_adaptive) #Calculate adaptive variance/covariance matrix
mu<-optima+dmX%*%beta #Simulate mu for Y
Y<-MASS::mvrnorm(n=1,mu,V) #Simulate adaptive model Y trait
df<-data.frame(Y=Y,X=X)
names(df)<-c("Y","X")
ggplot2::ggplot(data=df,ggplot2::aes(x=X,y=Y))+
ggplot2::geom_point()
summary(lm(Y~X,df))
#>
#> Call:
#> lm(formula = Y ~ X, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.76863 -0.28298 -0.00467 0.27014 0.74924
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 1.91827 0.05439 35.27 < 2e-16 ***
#> X 0.19999 0.04902 4.08 0.000169 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.3417 on 48 degrees of freedom
#> Multiple R-squared: 0.2575, Adjusted R-squared: 0.242
#> F-statistic: 16.65 on 1 and 48 DF, p-value: 0.000169Simulating measurement error
Next we will simulate measurement error - we will use a standard deviation of measurement error of 0.01, which we will provide to Blouch as a vector (X_error and Y_error), and use the rnorm function to add error to our X and Y variables. In other words, we are telling Blouch that the estimated error on X and Y is 0.01, and providing it with X and Y variables that are offset by a random amount of error with this standard deviation.
Data setup for Blouch
Next we will use the treeplyr package (Uyeda and Harmon, 2014) make.treedata function to combine the data and tree based on the taxa names. See https://github.com/uyedaj/treeplyr for more on this package.
############################################################################################################
#Make trdata file
trait.data<-data.frame(cbind(Y_with_error,Y_error,X_with_error,X_error))
trdata<-treeplyr::make.treedata(phy,trait.data)
############################################################################################################Next we set the priors following the format above
########################################################################################################
#Set Priors
hl.prior<-c(log(0.25),0.75)
vy.prior<-5
optima.prior<-c(2,0.2) #Informed by linear model
beta.prior<-c(0,0.25) #Informed by linear model
#View priors in Prior and Posterior Plots Code.RmdExploring Priors
At this point one would want to explore if the priors are appropriate - do the prior distributions look consistent with what we know about our system? See Grabowski (in press) for more on setting priors.
Half-life Prior plot
hl.sims<-data.frame(rlnorm(n=1000,meanlog=hl.prior[1],sdlog=hl.prior[2]))
names(hl.sims)<-"prior.hl.sims"
hl.prior.plot<-ggplot2::ggplot()+
ggplot2::geom_density(ggplot2::aes(prior.hl.sims,fill="prior.hl.sims"),alpha=0.2,data=hl.sims)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#labs(title="Prior vs. Posterior Distribution ",x="Half-life", y = "Density")+
ggplot2::labs(title="",x="Half-life", y = "Density")+
#scale_fill_manual(labels=c("Posterior","Prior"))+
ggplot2::geom_vline(xintercept=c(hl),linetype=2)+
ggsci::scale_fill_npg(name="",labels=c("Prior"))
hl.prior.plot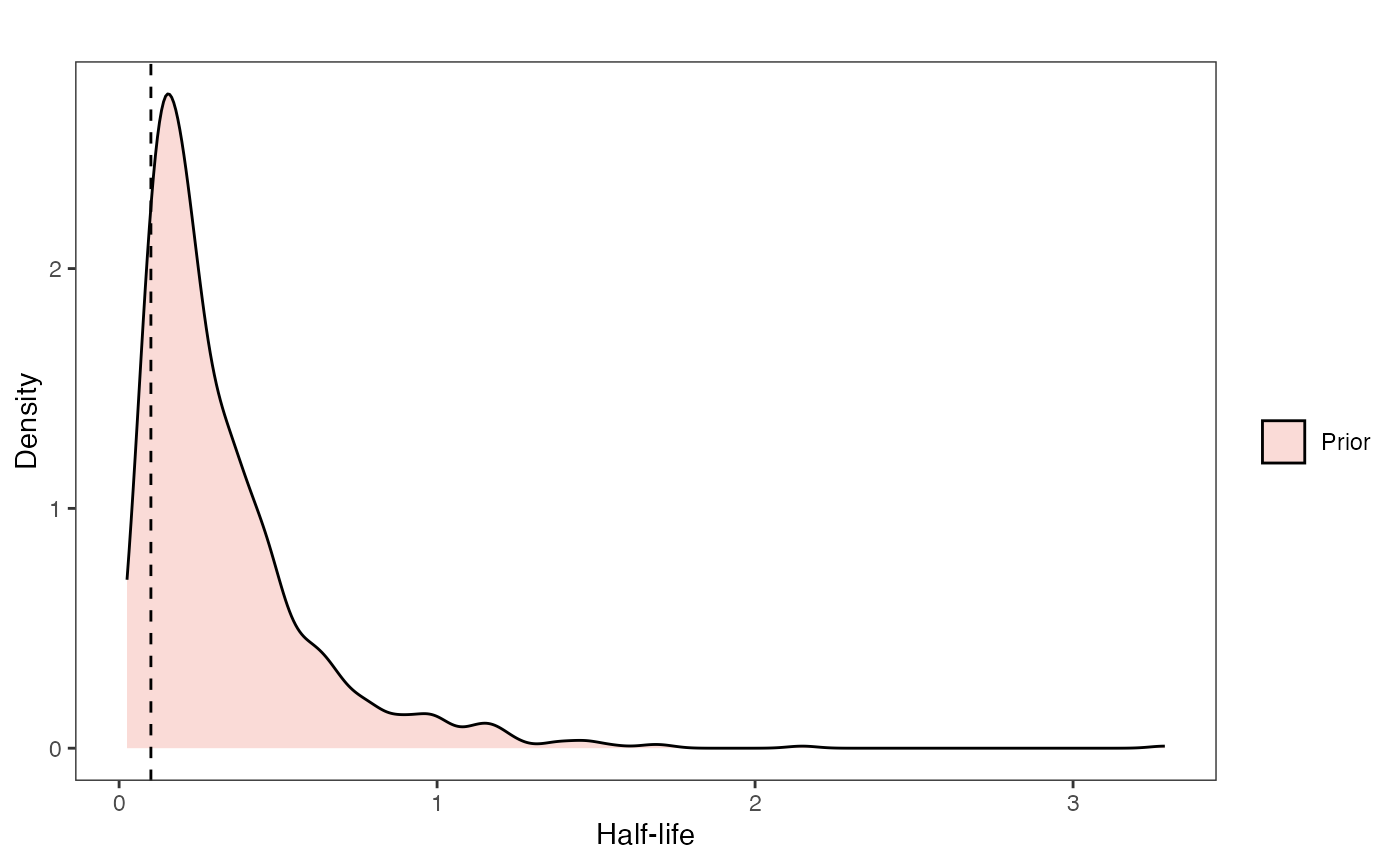
Vy Prior Plot
vy.sims<-rexp(n=1000,rate=vy.prior)
vy.sims<-data.frame(vy.sims)
names(vy.sims)<-"prior.vy.sims"
vy.prior.plot<-ggplot2::ggplot()+
ggplot2::geom_density(ggplot2::aes(prior.vy.sims,fill="prior.vy.sims"),alpha=0.2,data=vy.sims)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#labs(title="Prior vs. Posterior Distribution ",x="vy", y = "Density")+
ggplot2::labs(title="",x="vy", y = "Density")+
ggplot2::geom_vline(xintercept=c(vy),linetype=2)+
#scale_fill_manual(labels=c("Posterior","Prior"))+
ggsci::scale_fill_npg(name="",labels=c("Prior"))
vy.prior.plot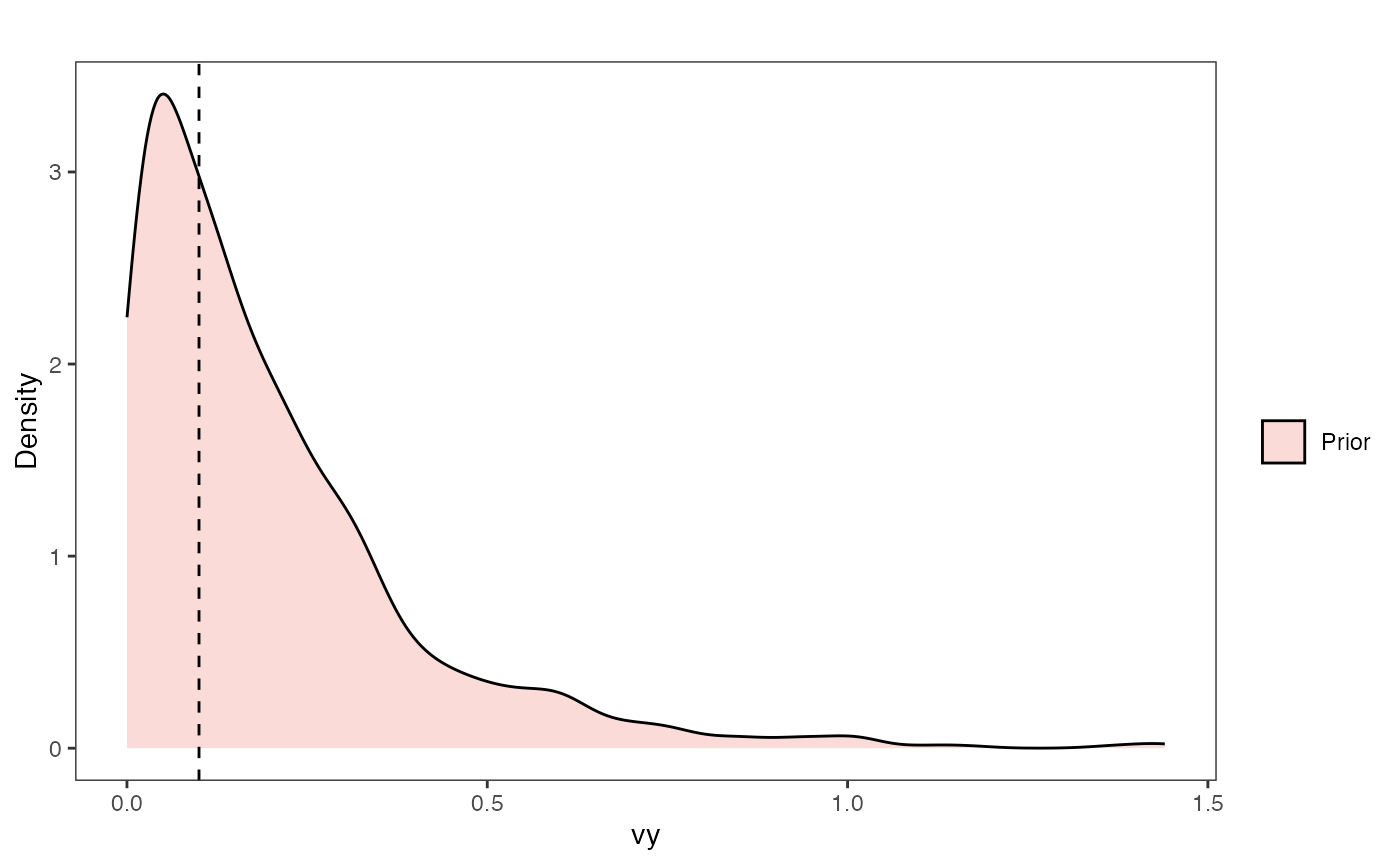
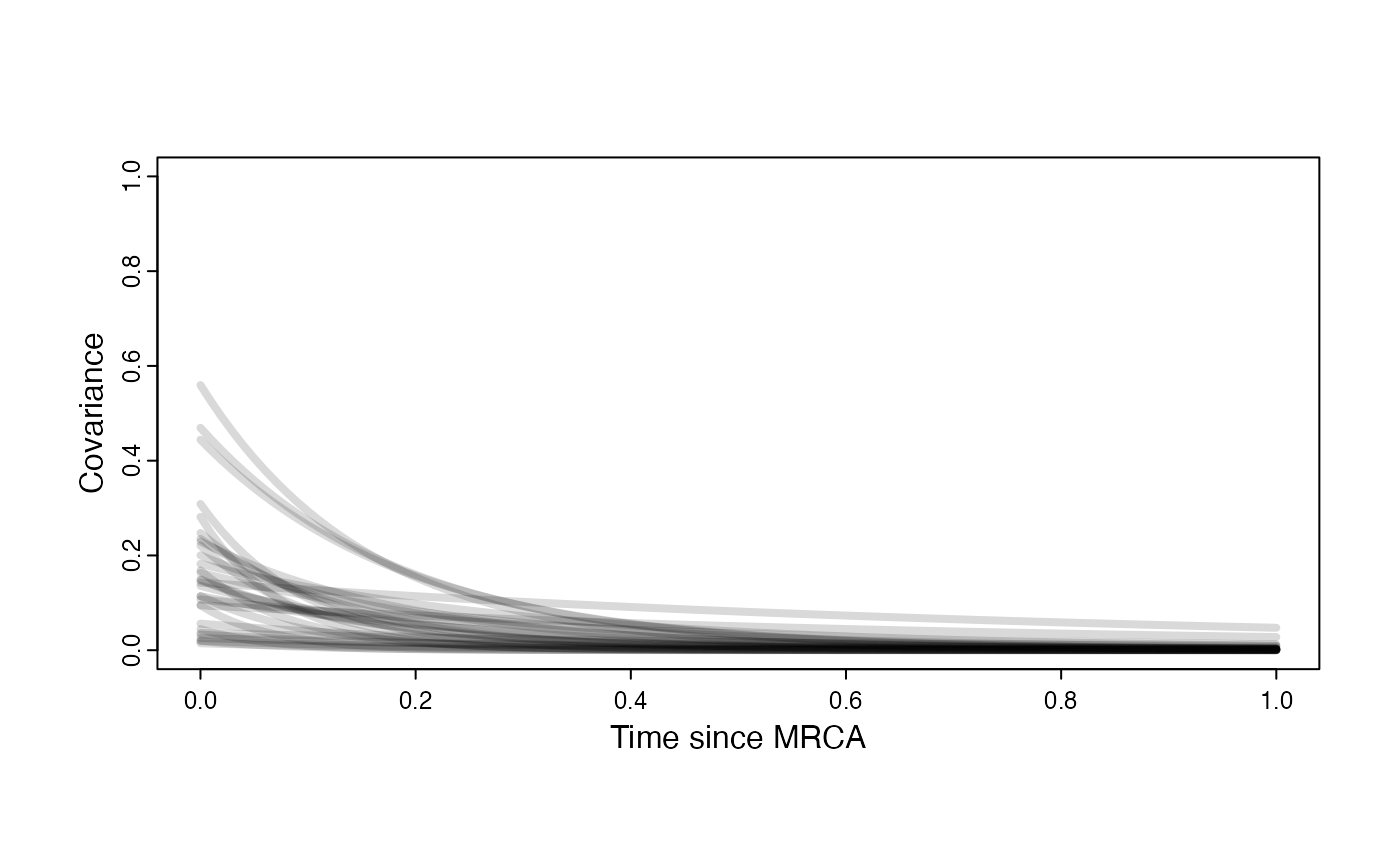
Prior on how shared branch lengths correspond to covariance
a.sims<-log(2)/hl.sims;
sigma2_y.sims<-vy.sims*(2*(log(2)/hl.sims));
plot( NULL , xlim=c(0,1) , ylim=c(0,1) , xlab="Time since MRCA" , ylab="Covariance" ,cex.axis=0.75, mgp=c(1.25,0.25,0),tcl=-0.25)
for (i in 1:30){
curve(calc_adaptive_cov_plot(a.sims[i,],sigma2_y.sims[i,],beta,x) , add=TRUE , lwd=4 , col=rethinking::col.alpha(1,0.15))
}
par(mar=c(3,3,0.25,0.25))
covariance.prior.plot <- recordPlot()
dev.off()
#> null device
#> 1
covariance.prior.plotSlope and intercept Prior Plot
optima.sims<-rnorm(100,optima.prior[1],optima.prior[2])
beta.sims<-rnorm(n=100,beta.prior[1],beta.prior[2])
prior.slope.plot<-ggplot2::ggplot()+
ggplot2:: geom_point(data=df,ggplot2::aes(y=Y,x=X))+
ggplot2::geom_abline(intercept=optima.sims,slope=beta.sims,alpha=0.15)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
ggplot2::ylab("Y") + ggplot2::xlab("Adaptive X")+
ggsci::scale_color_npg()
prior.slope.plot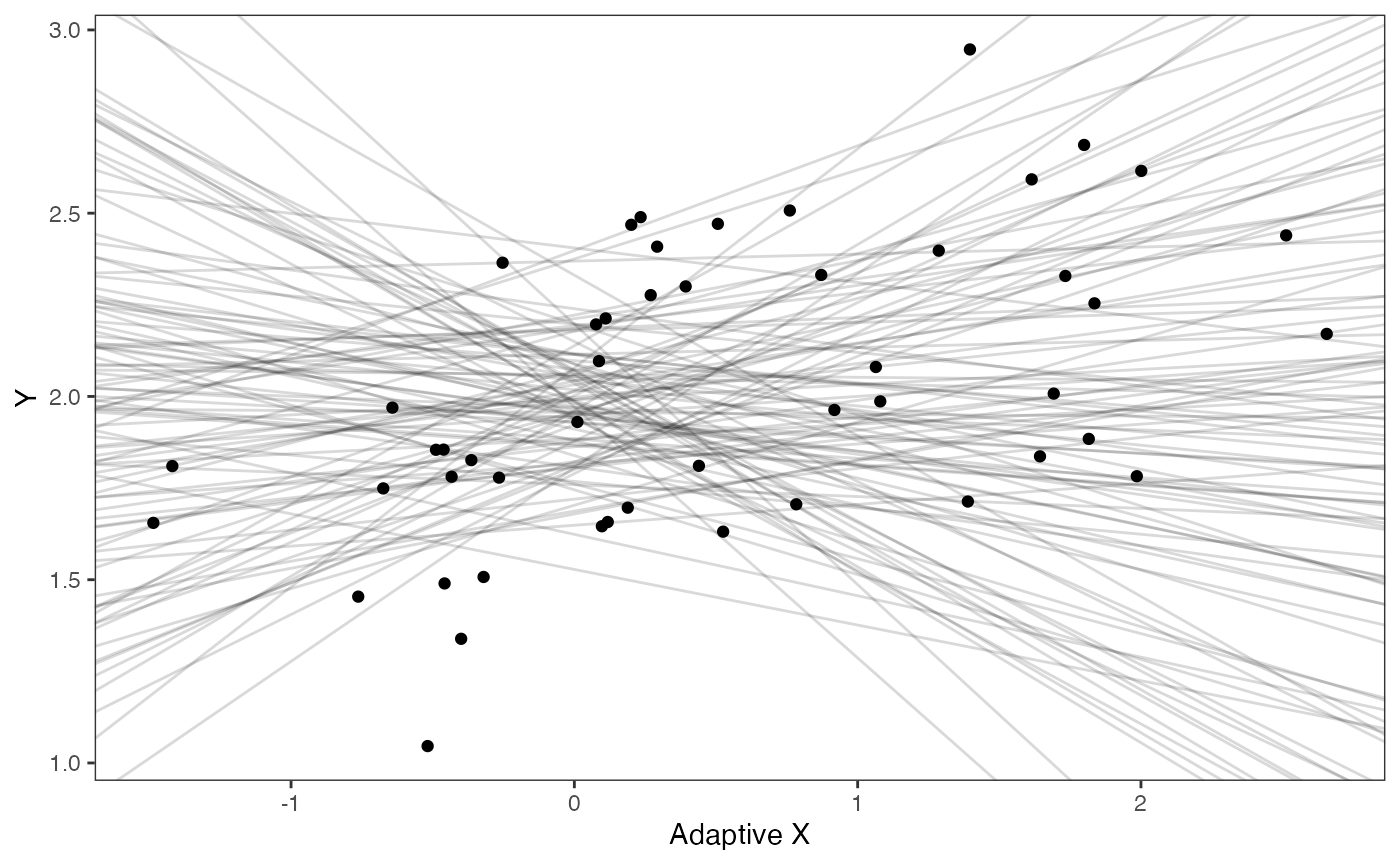
We will use the helper function blouch.adapt.prep() to setup the dat file for Stan. Here the name of the column in trdata$dat that contains the response variable is “Y_with_error”, the associated error column name is “Y_error,” the direct effect predictor column is named “X_with_error”, and its associated errors is “X_error”. Finally, we give the helper function the number of predictor traits, 1 here, and the prior distributions on the parameters.
#Test Blouch prep code - adaptive model
dat<-blouch.adapt.prep(trdata,"Y_with_error","Y_error","X_with_error","X_error",hl.prior,vy.prior,optima.prior,beta.prior)Running models
Below are the priors used for this simulation. See Grabowski (in press) for more on setting these priors. To change these values requires you to open the Stan function, in this case blouchOU_direct, and manually edit them. Unfortunately there is no way around this at present, but trust me - it will be worth it.
For example, here are the four most important priors for the model below - these values are explored in Grabowski (in press). Remember, always do prior predictive simulations first - in other words, look at distributions of the values and see if they are actually biologically possible - see the exploring priors step above.
########################################################################################################
#Priors
#hl ~ lognormal(log(0.25),0.25);
#vy ~ exponential(5);
#alpha ~ normal(2.0,0,2);
#beta ~ normal(0.25,0.1); And here are the lines of Stan code for setting these priors. To change the values to make them appropriate for your own analyses, you just need to change the numbers below. All Stan programs are in the Blouch/inst/stan folder and named according to the model they run. See Table S1 of Grabowski (in press) for more on the models. Remember, your priors should be based on what you know about the biological processes underlying your research question and prior predictive simulations (see McElreath 2020).
#Stan CodeNow let’s run the adaptive model blouchOU_adapt
fit.adapt<- rstan::sampling(object = blouch:::stanmodels$blouchOU_adapt,data = dat,chains = 2,cores=2,iter =2000)
#> Found more than one class "stanfit" in cache; using the first, from namespace 'rstan'
#> Also defined by 'rethinking'
#> Found more than one class "stanfit" in cache; using the first, from namespace 'rstan'
#> Also defined by 'rethinking'Here the results include both the optimal regression, beta, and the evolutionary regression, beta_e, following Hansen et al. (2008)
print(fit.adapt,pars = c("hl","vy","optima","beta","beta_e"))
#> Inference for Stan model: blouchOU_adapt.
#> 2 chains, each with iter=2000; warmup=1000; thin=1;
#> post-warmup draws per chain=1000, total post-warmup draws=2000.
#>
#> mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
#> hl 0.14 0 0.07 0.06 0.10 0.13 0.18 0.32 1586 1
#> vy 0.15 0 0.04 0.09 0.12 0.14 0.17 0.25 2083 1
#> optima 1.94 0 0.09 1.77 1.88 1.94 1.99 2.12 3482 1
#> beta[1] 0.24 0 0.09 0.07 0.18 0.23 0.29 0.43 2090 1
#> beta_e[1] 0.19 0 0.07 0.05 0.14 0.19 0.23 0.32 1915 1
#>
#> Samples were drawn using NUTS(diag_e) at Sat Oct 18 11:56:21 2025.
#> For each parameter, n_eff is a crude measure of effective sample size,
#> and Rhat is the potential scale reduction factor on split chains (at
#> convergence, Rhat=1).
post<-rstan::extract(fit.adapt)Now lets look at the prior vs. posterior plots for the parameters Half-life plot
hl.post<-data.frame(post$hl)
names(hl.post)<-"post.hl.sims"
hl.plot<-ggplot2::ggplot()+
ggplot2::geom_density(ggplot2::aes(prior.hl.sims,fill="prior.hl.sims"),alpha=0.2,data=hl.sims)+
ggplot2::geom_density(ggplot2::aes(post.hl.sims,fill="post.hl.sims"),alpha=0.2,data=hl.post)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#labs(title="Prior vs. Posterior Distribution ",x="Half-life", y = "Density")+
ggplot2::labs(title="",x="Half-life", y = "Density")+
#scale_fill_manual(labels=c("Posterior","Prior"))+
ggplot2::geom_vline(xintercept=c(hl),linetype=2)+
ggsci::scale_fill_npg(name="",labels=c("Posterior","Prior"))
hl.plot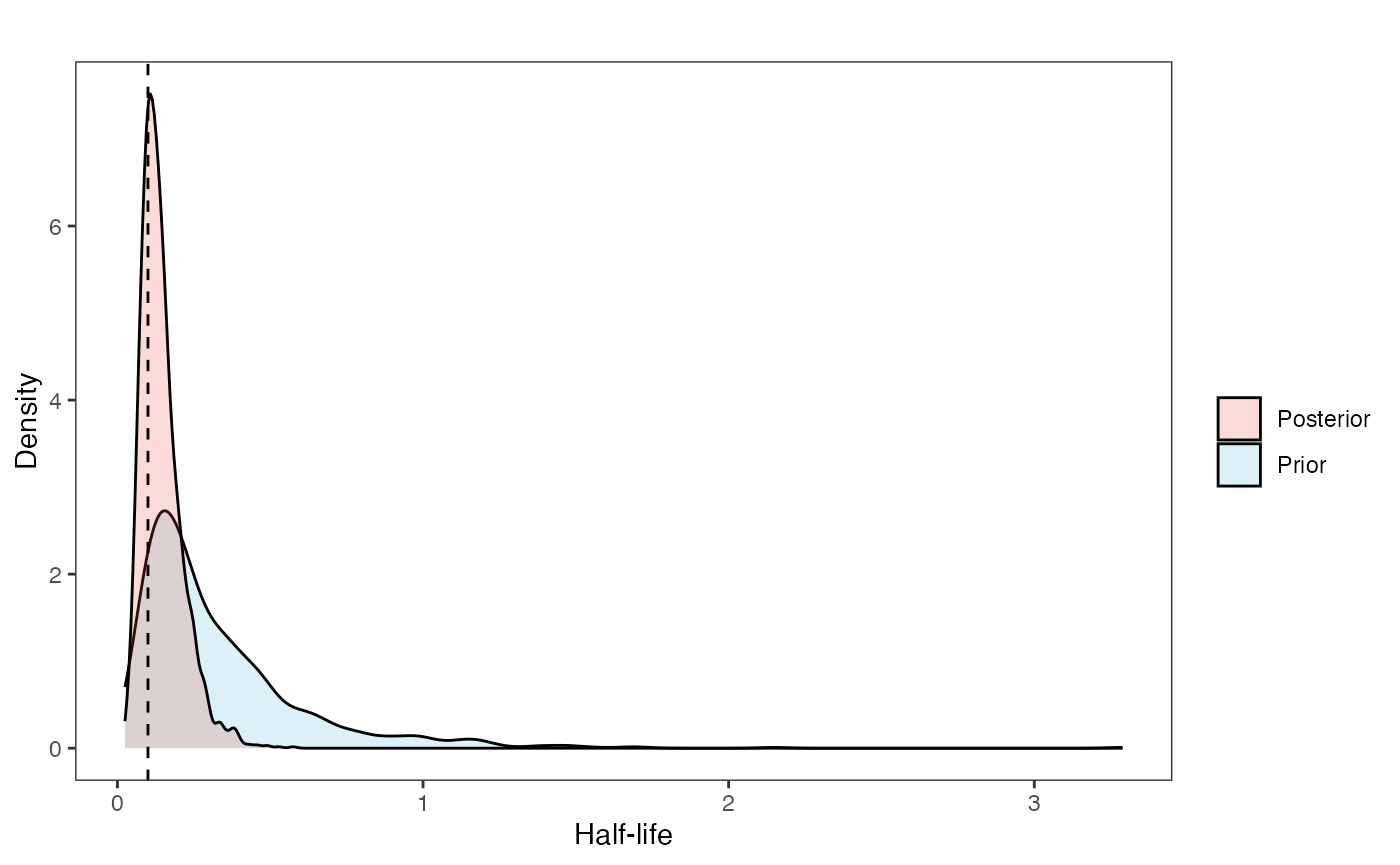
Vy Prior vs. posterior plot
vy.post<-data.frame(post$vy)
names(vy.post)<-"post.vy.sims"
vy.plot<-ggplot2::ggplot()+
ggplot2::geom_density(ggplot2::aes(prior.vy.sims,fill="prior.vy.sims"),alpha=0.2,data=vy.sims)+
ggplot2::geom_density(ggplot2::aes(post.vy.sims,fill="post.vy.sims"),alpha=0.2,data=vy.post)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#labs(title="Prior vs. Posterior Distribution ",x="vy", y = "Density")+
ggplot2::labs(title="",x="vy", y = "Density")+
ggplot2::geom_vline(xintercept=c(vy),linetype=2)+
#scale_fill_manual(labels=c("Posterior","Prior"))+
ggsci::scale_fill_npg(name="",labels=c("Posterior","Prior"))
vy.plot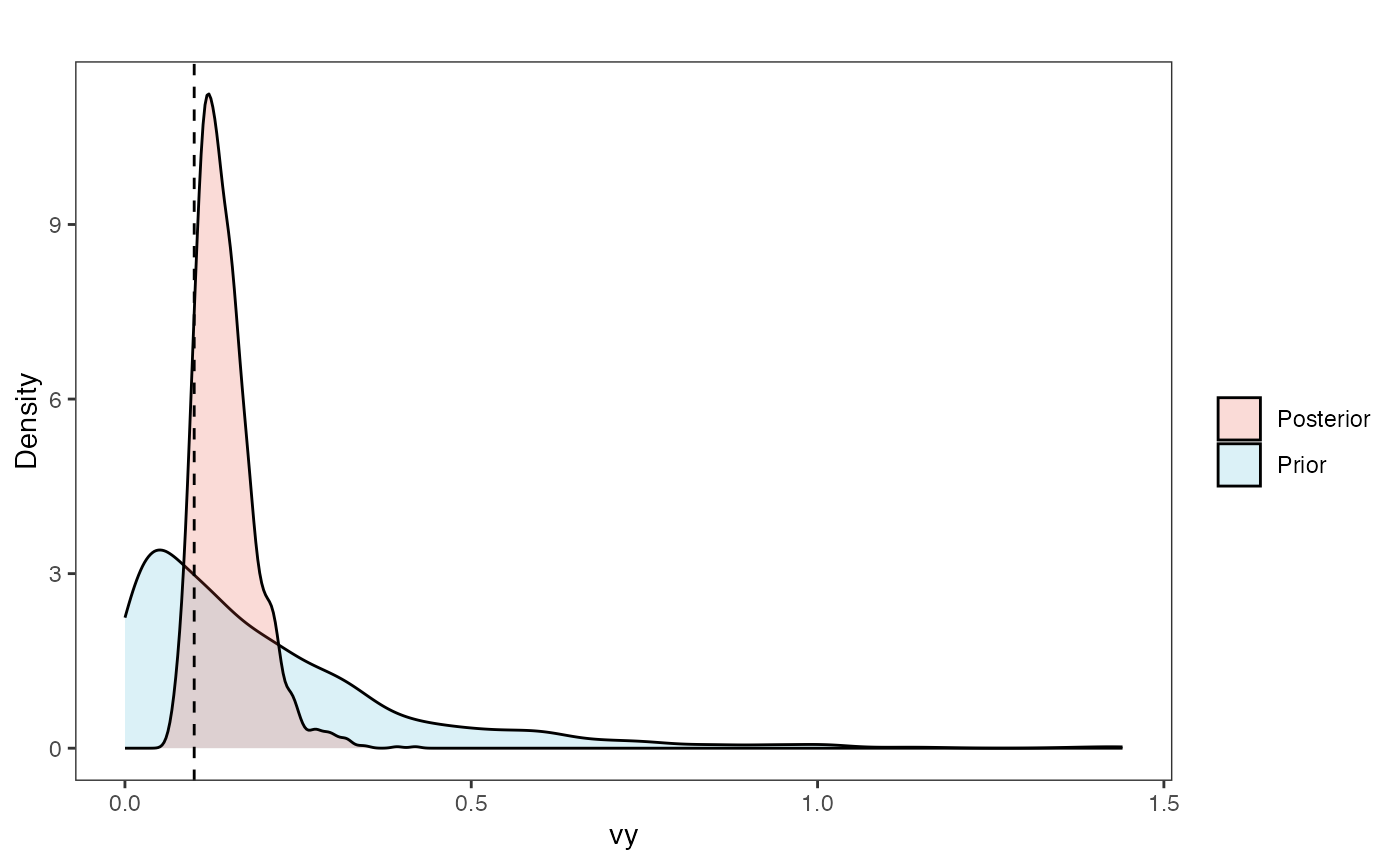
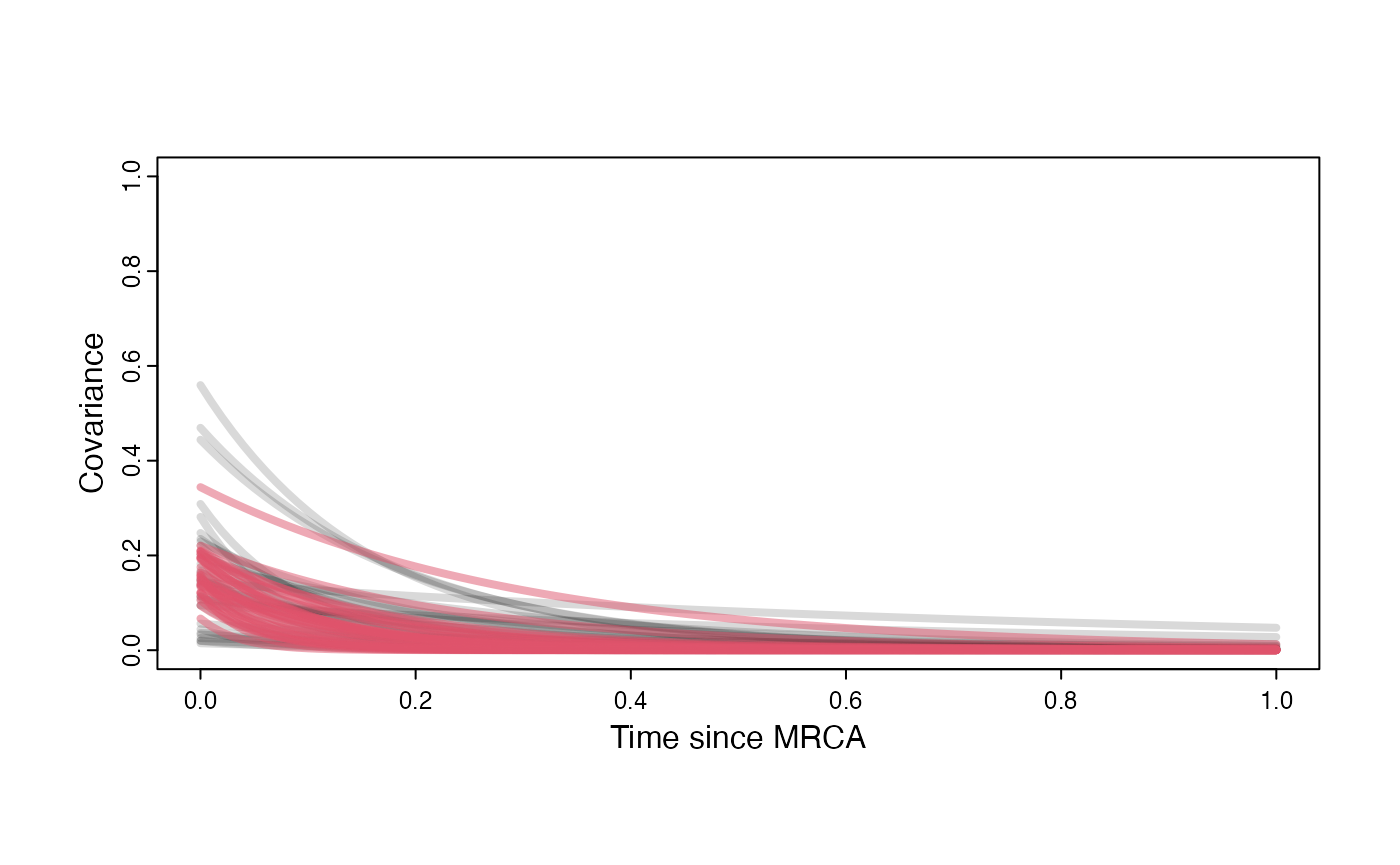
Prior versus posterior on how shared branch lengths correspond to covariance Adaptation model
a.sims<-log(2)/hl.sims;
sigma2_y.sims<-vy.sims*(2*(log(2)/hl.sims));
#x<-seq(from=0,to=1,by=0.001)
#V.sim<-calc_direct_V(phy,a.sims,sigma2_y.sims)
#calc_adaptive_V_plot<-function(phy,a, sigma2_y, beta, sigma2_x){
plot( NULL , xlim=c(0,1) , ylim=c(0,1) , xlab="Time since MRCA" , ylab="Covariance" ,cex.axis=0.75, mgp=c(1.25,0.25,0),tcl=-0.25)
for (i in 1:30){
curve(calc_adaptive_cov_plot(a.sims[i,],sigma2_y.sims[i,],beta,x) , add=TRUE , lwd=4 , col=rethinking::col.alpha(1,0.15))
}
for (i in 1:30){
curve(calc_adaptive_cov_plot(post$a[i],post$sigma2_y[i],post$beta[i],x) , add=TRUE , lwd=4 , col=rethinking::col.alpha(2,0.5))
}
par(mar=c(3,3,0.25,0.25))
covariance.plot <- recordPlot()
dev.off()
#> null device
#> 1
covariance.plotPrior vs. Posterior Plot for Regression
optima.sims<-rnorm(100,optima.prior[1],optima.prior[2])
beta.sims<-rnorm(n=100,beta.prior[1],beta.prior[2])
optima.post<-data.frame(post$optima)
names(optima.post)<-"post.optima"
beta.post<-data.frame(post$beta)
names(beta.post)<-"post.beta"
mu.link<-function(x.seq){optima.post+x.seq*beta.post}
x.seq <- seq(from=min(X), to=max(X) , length.out=100)
mu <- sapply(x.seq , mu.link )
mu.mean <-lapply( mu , mean )
mu.mean<-data.frame(as.numeric(mu.mean))
names(mu.mean)<-"mu.mean"
mu.CI <- lapply( mu ,rethinking:: PI , prob=0.89 )
mu.CI<-data.frame(t(data.frame(mu.CI)),x.seq)
names(mu.CI)<-c("min.5.5","max.94.5","x.seq")
#df<-data.frame(Y=stan_sim_data$Y,X=stan_sim_data$direct_cov)
df<-data.frame(Y=Y,X=X)
names(df)<-c("Y","X")
df2<-data.frame(x.seq,mu.mean)
#slope.prior.plot<-ggplot(data=reg.trdata$dat,aes(y=Sim1,x=X))+
slope.plot<-ggplot2::ggplot()+
ggplot2::geom_point(data=df,ggplot2::aes(y=Y,x=X))+
ggplot2::geom_abline(intercept=optima.sims,slope=beta.sims,alpha=0.15)+
ggplot2::geom_abline(intercept=optima,slope=beta,alpha=0.5,linetype=2)+
ggplot2::geom_line(data=df2,ggplot2::aes(x=x.seq,y=mu.mean),linetype=1)+
ggplot2::geom_ribbon(data=mu.CI,ggplot2::aes(x=x.seq,ymin=min.5.5,ymax=max.94.5),linetype=2,alpha=0.25)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#ggtitle("Prior vs. Posterior for Intercept and Slope")+
ggplot2::ylab("Y") + ggplot2::xlab("Adaptive X")+
ggsci::scale_color_npg()
slope.plot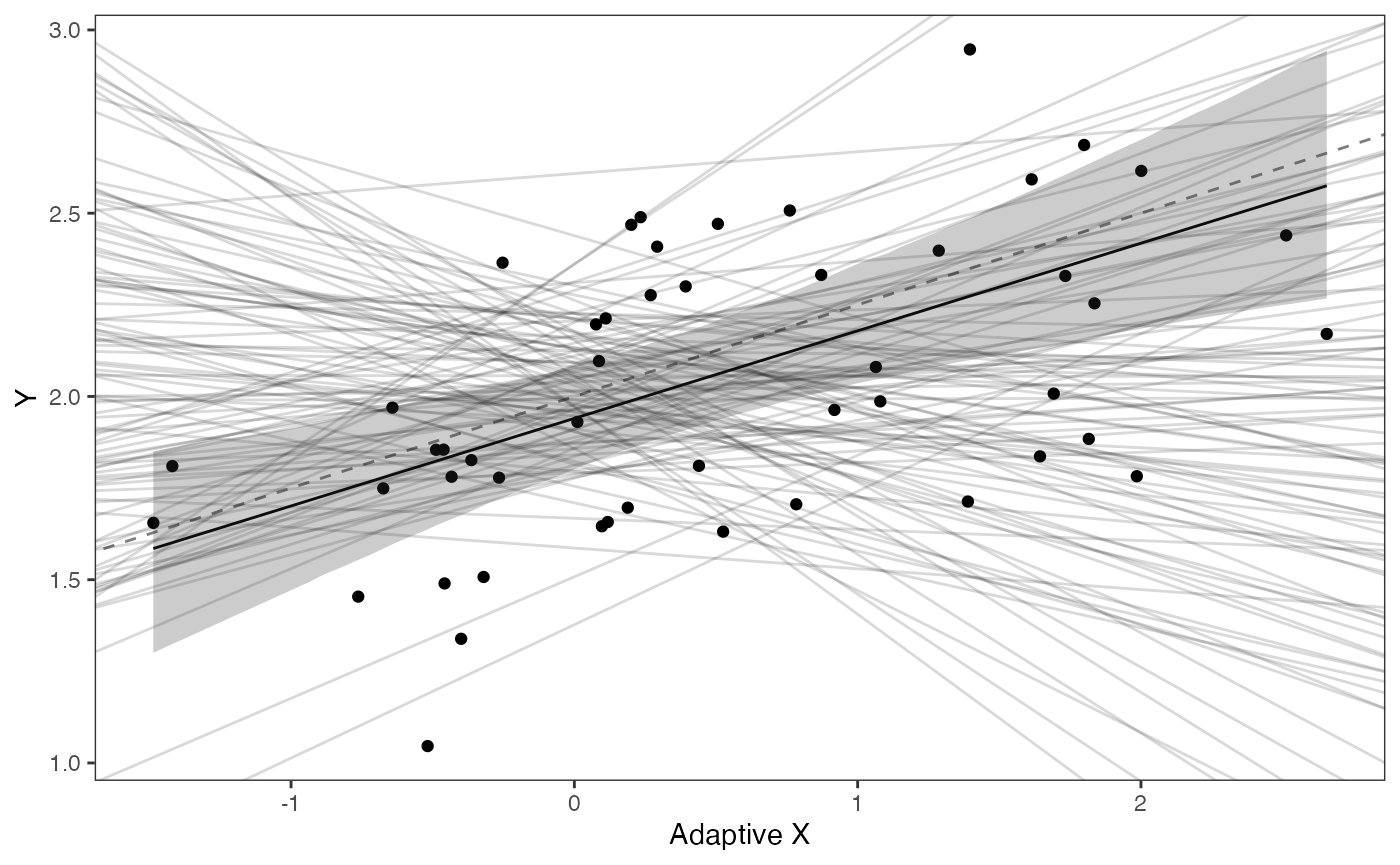
Direct effect and adaptive models
Finally, we can look at models that are a combination of direct effect and adaptive traits. Setup is similar to above except here we have two predictors.
First we will create a phylogeny by randomly sampling from the 10K Trees phylogeny
########################################################################################################
#Create phylogeny
########################################################################################################
N<-50 #Number of species
set.seed(10) #Set seed to get same random species each time
phy <- ape::keep.tip(tree.10K,sample(tree.10K$tip.label)[1:N])
phy<-ape::multi2di(phy)
l.tree<-max(ape::branching.times(phy)) ## rescale tree to height 1
phy$edge.length<-phy$edge.length/l.tree
tip.label<-phy$tip.labelSet true/known parameter values
We will simulate X and Y data using a generative model for the direct effect and adaptive model. Here we will have 1 direct effect trait, Xd, and one adaptive trait, Xa. An object Z always refers to the number of traits, in this case Z_direct = number of direct effect traits, and Z_adaptive = number of adaptive traits. Because this is a simulation we are setting the instantaneous variance of the BM process (sigma2_x) to 1, which needs to be in matrix format. Normally Blouch estimates this as part of the blouch.direct.adapt.prep helper function.
############################################################################################################
#Direct effect + Adaptive Model
############################################################################################################
hl<-0.1 #0.1, 0.25, 0.75 - testing options
a<-log(2)/hl
vy<-0.01 #0.25,0.5 - testing options
sigma2_y<-vy*(2*(log(2)/hl));
vX0<-0
vY0 <- 0
Z_direct<-1
Z_adaptive<-1
Z<-Z_direct+Z_adaptive
sigma2_x<-matrix(1,1,1) #Variance of BM Process
Xd<-rnorm(N,0,1)
names(Xd)<-phy$tip.label
phytools::phenogram(phy,Xd,spread.labels=TRUE,spread.cost=c(1,0)) #Plot X data
#> Optimizing the positions of the tip labels...
Xa<-phytools::fastBM(phy,a=vX0,sig2=sigma2_x[1,1],internal=FALSE) #Simulate X BM variable on tree, with scaling 10
phytools::phenogram(phy,Xa,spread.labels=TRUE,spread.cost=c(1,0)) #Plot X data
#> Optimizing the positions of the tip labels...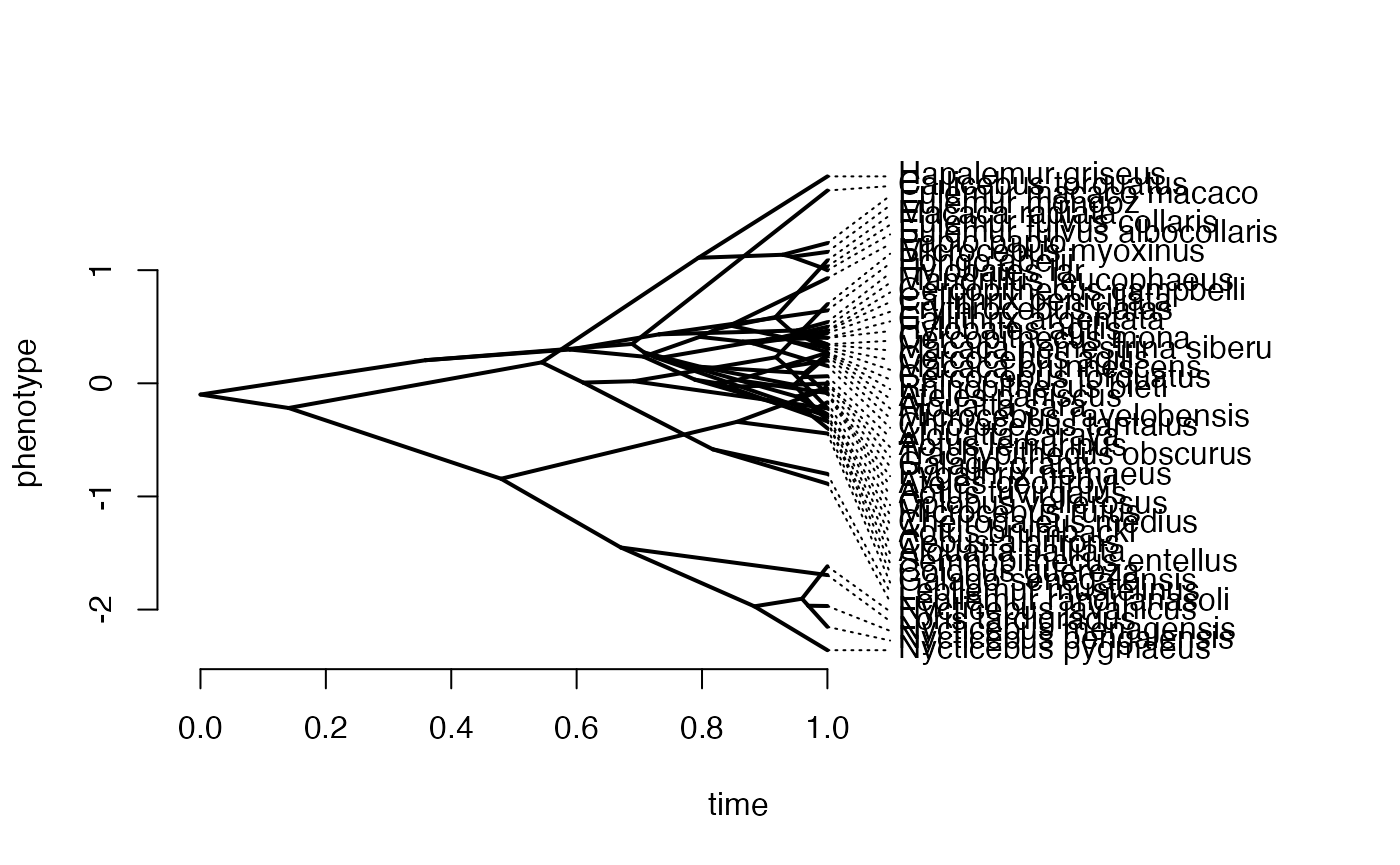
Xs<-cbind(Xd,Xa)We will have one intercept term here, but two slopes - the order in Blouch is always direct effect predictors first, followed by adaptive predictors. Thus the direct effect slope will be 0.35 and the adaptive slope will be 0.25. Except for the Blouch helper function calc_mixed_dmX, which is used when there are mixed design matrices, the other functions are the same as the adaptive model above. One complication is the beta term below in the calc_adaptive_V function call - we are sending this function only the adaptive slope and the line beta[(Z_direct+1):(Z_adaptive+Z_direct)] is one way of specifying only that term.
Finally we make a quick plot of the results.
optima<-2 #Intecept
beta<-c(0.35,0.25) #Slopes
dmX<-calc_mixed_dmX(phy,a,Xs,Z_direct,Z_adaptive)
mu<-optima+dmX%*%beta #Simulate mu for Y
V<-calc_adaptive_V(phy,a, sigma2_y, beta[(Z_direct+1):(Z_adaptive+Z_direct)], sigma2_x, Z_adaptive)
Y<-MASS::mvrnorm(n=1,mu,V)
df<-data.frame(Y=Y,X=Xs)
summary(lm(Y~Xs,df))
#>
#> Call:
#> lm(formula = Y ~ Xs, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.238679 -0.059603 0.004496 0.053077 0.163165
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 1.97929 0.01391 142.32 <2e-16 ***
#> XsXd 0.35619 0.01019 34.94 <2e-16 ***
#> XsXa 0.24084 0.01588 15.17 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.0977 on 47 degrees of freedom
#> Multiple R-squared: 0.9706, Adjusted R-squared: 0.9694
#> F-statistic: 775.9 on 2 and 47 DF, p-value: < 2.2e-16
ggplot2::ggplot(data=df,ggplot2::aes(x=X.Xd,y=Y))+
ggplot2::geom_point()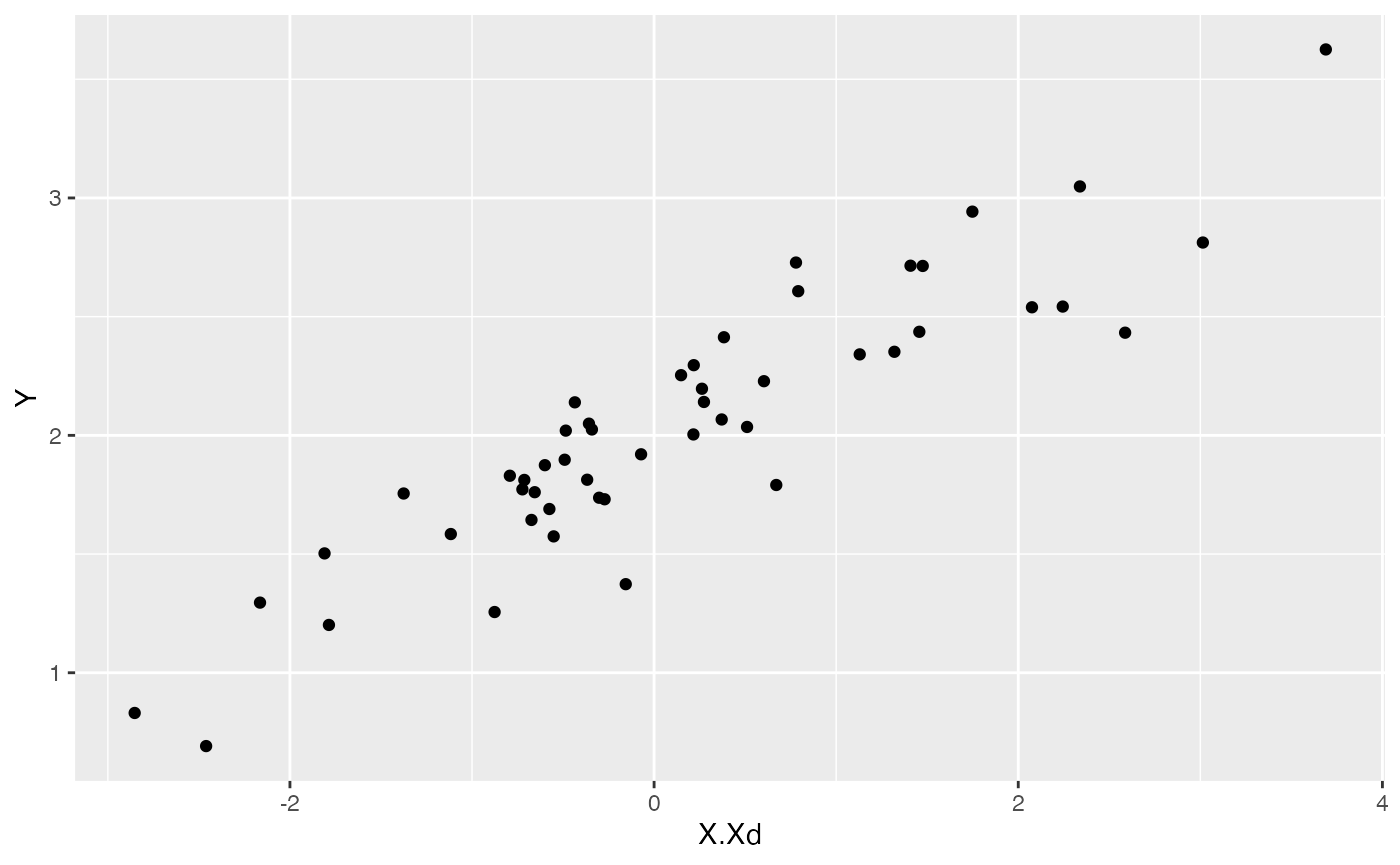
summary(lm(Y~X.Xd,df))
#>
#> Call:
#> lm(formula = Y ~ X.Xd, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.56057 -0.12940 0.01279 0.18762 0.44894
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 1.99121 0.03335 59.70 <2e-16 ***
#> X.Xd 0.36927 0.02440 15.13 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.2347 on 48 degrees of freedom
#> Multiple R-squared: 0.8267, Adjusted R-squared: 0.8231
#> F-statistic: 229 on 1 and 48 DF, p-value: < 2.2e-16
ggplot2::ggplot(data=df,ggplot2::aes(x=X.Xa,y=Y))+
ggplot2::geom_point()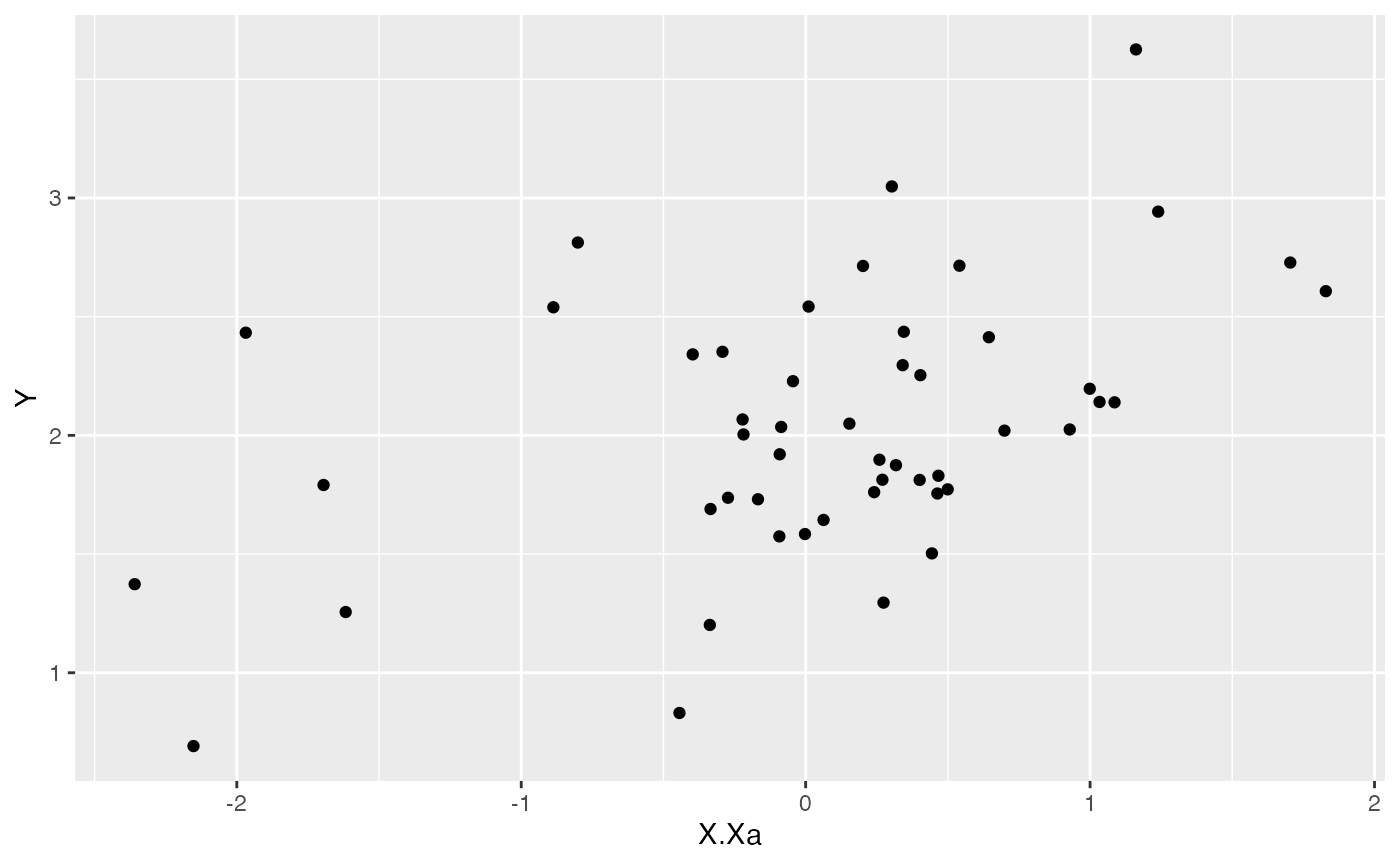
summary(lm(Y~X.Xa,df))
#>
#> Call:
#> lm(formula = Y ~ X.Xa, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.06619 -0.32149 -0.09678 0.24479 1.26696
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 2.02444 0.07117 28.446 < 2e-16 ***
#> X.Xa 0.28776 0.08133 3.538 0.000905 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.5022 on 48 degrees of freedom
#> Multiple R-squared: 0.2069, Adjusted R-squared: 0.1903
#> F-statistic: 12.52 on 1 and 48 DF, p-value: 0.0009055Next we will simulate measurement error - we will use a standard deviation of measurement error of 0.01, which we will provide to Blouch as a vector (X_error and Y_error), and use the rnorm function to add error to our X and Y variables. In other words, we are telling Blouch that the estimated error on X and Y is 0.01, and providing it with X and Y variables that are offset by a random amount of error with this standard deviation. The complication here is we are simulating error in more than one trait - both an adaptive and direct effect trait - the extra lines of code below do this.
########################################################################################################
#Simulate errors - for use with blouchOU_reg_direct_adaptive_ME
Z_X_error<-2 #Number of X traits with error
X_error<-matrix(0.01,nrow=N,ncol=Z_X_error)
X_error<-data.frame(X_error)
names(X_error)<-c("Xd_error","Xa_error")
Y_error<-rep(0.01,N)
Y_with_error<-Y+rnorm(N,0,0.01)
X_with_error<-apply(Xs,2,function(X){X+rnorm(N,0,0.01)})Data setup for Blouch
Next we will use the treeplyr package (Uyeda and Harmon, 2014) make.treedata function to combine the data and tree based on the taxa names. See https://github.com/uyedaj/treeplyr for more on this package.
############################################################################################################
#Make trdata file
trait.data<-data.frame(cbind(Y_with_error,Y_error,X_with_error,X_error))
trdata<-treeplyr::make.treedata(phy,trait.data)Next we set the priors following the format above - see above for exploring the priors
########################################################################################################
#Set Priors
hl.prior<-c(log(0.25),0.75)
vy.prior<-5
optima.prior<-c(2,0.2) #Informed by linear model
beta.prior<-c(0,0.25) #Informed by linear model
#View priors in Prior and Posterior Plots Code.RmdExploring Priors
At this point one would want to explore if the priors are appropriate - do the prior distributions look consistent with what we know about our system? See Grabowski (in press) for more on setting priors.
Half-life Prior plot
hl.sims<-data.frame(rlnorm(n=1000,meanlog=hl.prior[1],sdlog=hl.prior[2]))
names(hl.sims)<-"prior.hl.sims"
hl.prior.plot<-ggplot2::ggplot()+
ggplot2::geom_density(ggplot2::aes(prior.hl.sims,fill="prior.hl.sims"),alpha=0.2,data=hl.sims)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#labs(title="Prior vs. Posterior Distribution ",x="Half-life", y = "Density")+
ggplot2::labs(title="",x="Half-life", y = "Density")+
#scale_fill_manual(labels=c("Posterior","Prior"))+
ggplot2::geom_vline(xintercept=c(hl),linetype=2)+
ggsci::scale_fill_npg(name="",labels=c("Prior"))
hl.prior.plot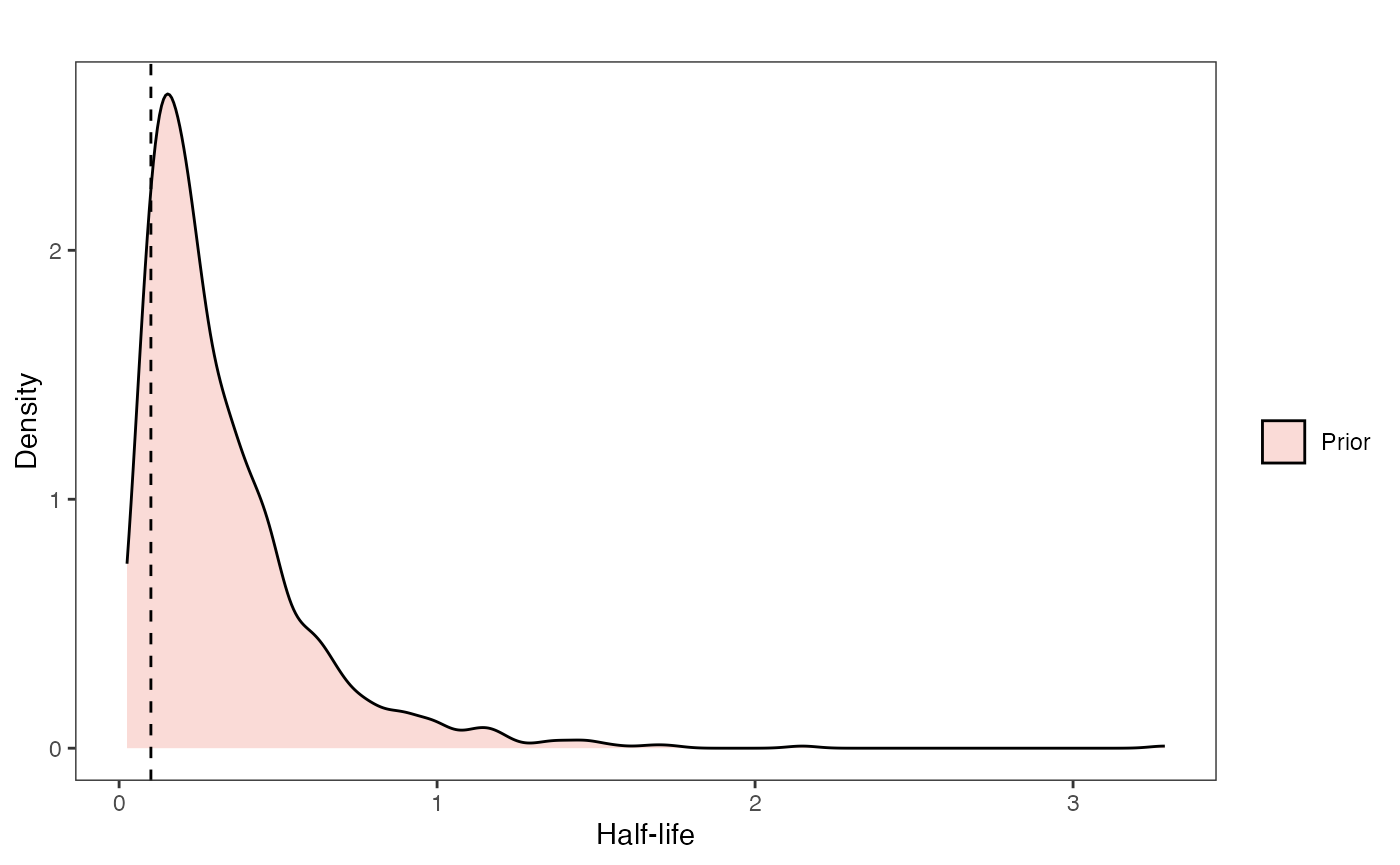
Vy Prior Plot
vy.sims<-rexp(n=1000,rate=vy.prior)
vy.sims<-data.frame(vy.sims)
names(vy.sims)<-"prior.vy.sims"
vy.prior.plot<-ggplot2::ggplot()+
ggplot2::geom_density(ggplot2::aes(prior.vy.sims,fill="prior.vy.sims"),alpha=0.2,data=vy.sims)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#labs(title="Prior vs. Posterior Distribution ",x="vy", y = "Density")+
ggplot2::labs(title="",x="vy", y = "Density")+
ggplot2::geom_vline(xintercept=c(vy),linetype=2)+
#scale_fill_manual(labels=c("Posterior","Prior"))+
ggsci::scale_fill_npg(name="",labels=c("Prior"))
vy.prior.plot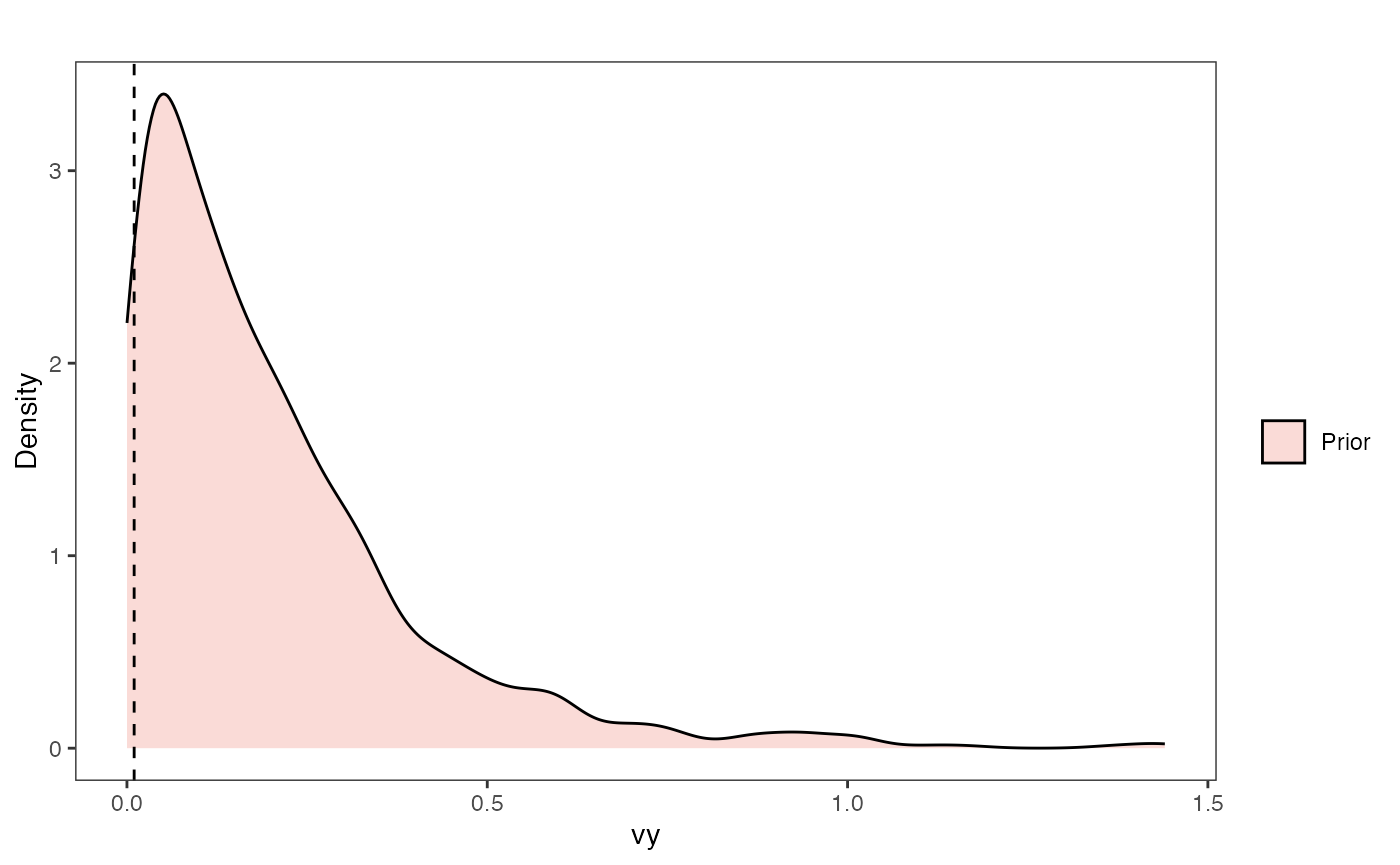
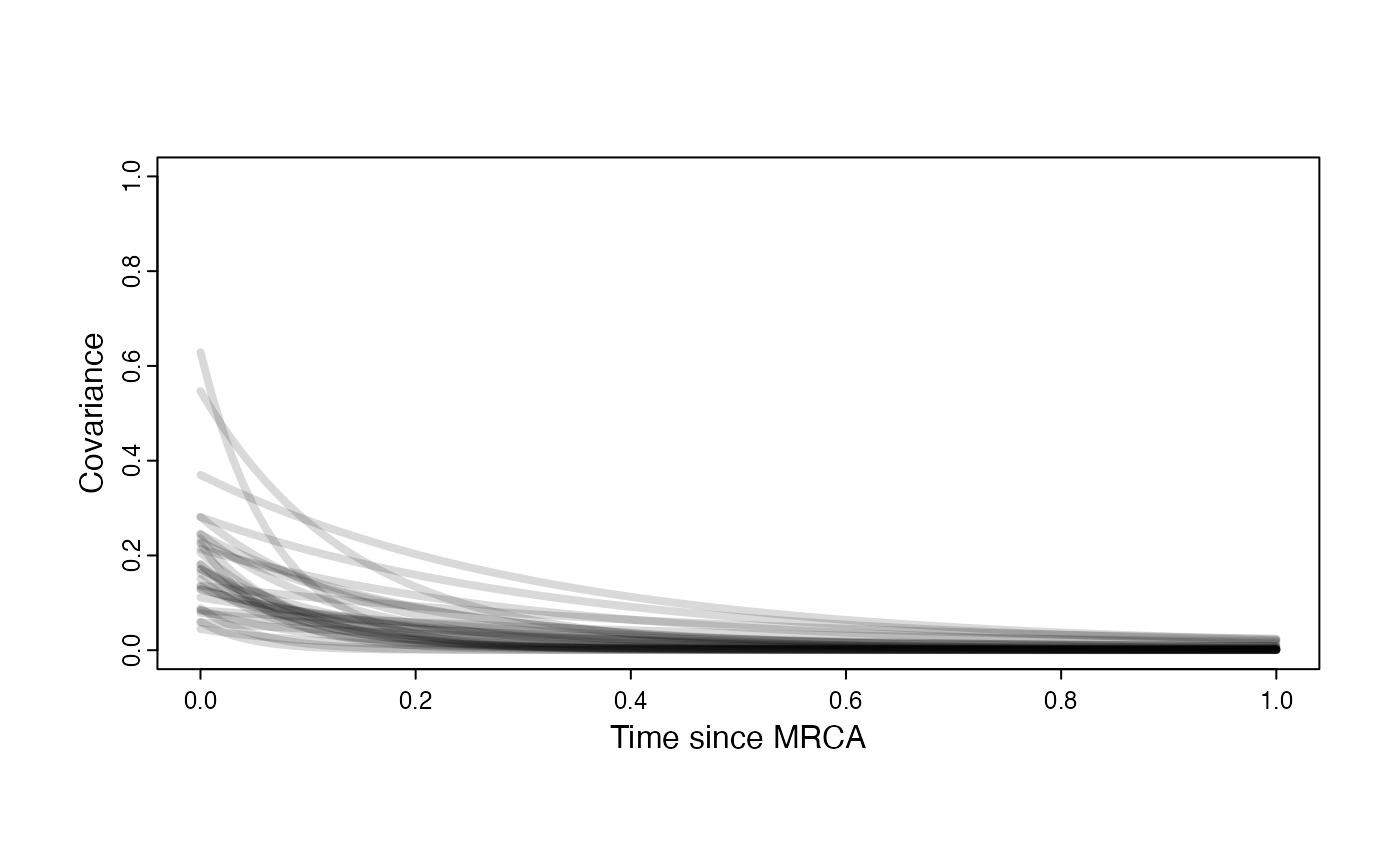
Prior on how shared branch lengths correspond to covariance
a.sims<-log(2)/hl.sims;
sigma2_y.sims<-vy.sims*(2*(log(2)/hl.sims));
plot( NULL , xlim=c(0,1) , ylim=c(0,1) , xlab="Time since MRCA" , ylab="Covariance" ,cex.axis=0.75, mgp=c(1.25,0.25,0),tcl=-0.25)
for (i in 1:30){
curve(calc_adaptive_cov_plot(a.sims[i,],sigma2_y.sims[i,],beta,x) , add=TRUE , lwd=4 , col=rethinking::col.alpha(1,0.15))
}
par(mar=c(3,3,0.25,0.25))
covariance.prior.plot <- recordPlot()
dev.off()
#> null device
#> 1
covariance.prior.plotSlope and intercept Prior Plot
optima.sims<-rnorm(100,optima.prior[1],optima.prior[2])
beta.sims<-rnorm(n=100,beta.prior[1],beta.prior[2])
prior.direct.slope.plot<-ggplot2::ggplot()+
ggplot2:: geom_point(data=df,ggplot2::aes(y=Y,x=X.Xd))+
ggplot2::geom_abline(intercept=optima.sims,slope=beta.sims,alpha=0.15)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
ggplot2::ylab("Y") + ggplot2::xlab("Direct Effect X")+
ggsci::scale_color_npg()
prior.direct.slope.plot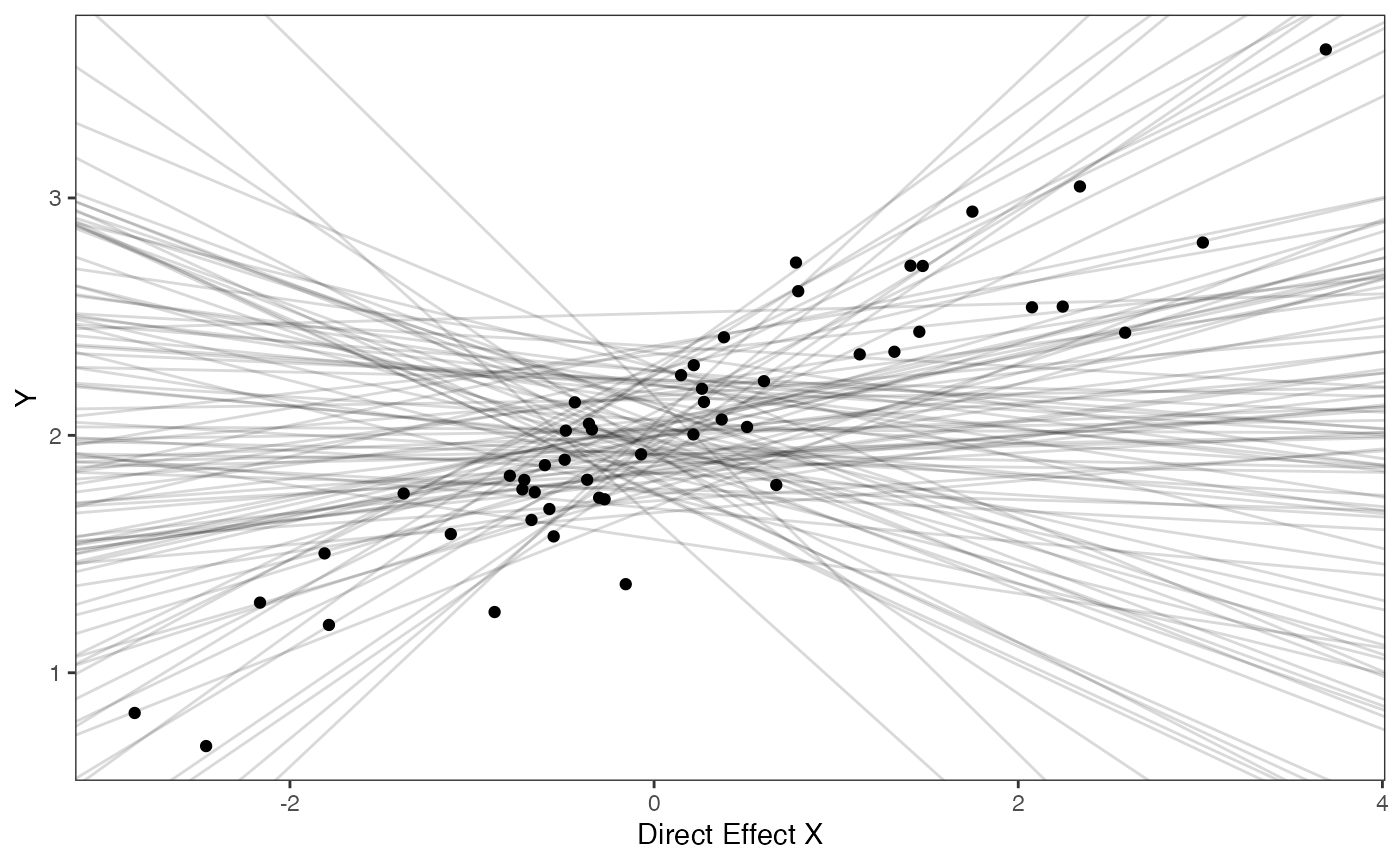
prior.adapt.slope.plot<-ggplot2::ggplot()+
ggplot2:: geom_point(data=df,ggplot2::aes(y=Y,x=X.Xa))+
ggplot2::geom_abline(intercept=optima.sims,slope=beta.sims,alpha=0.15)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
ggplot2::ylab("Y") + ggplot2::xlab("Adaptive X")+
ggsci::scale_color_npg()
prior.adapt.slope.plot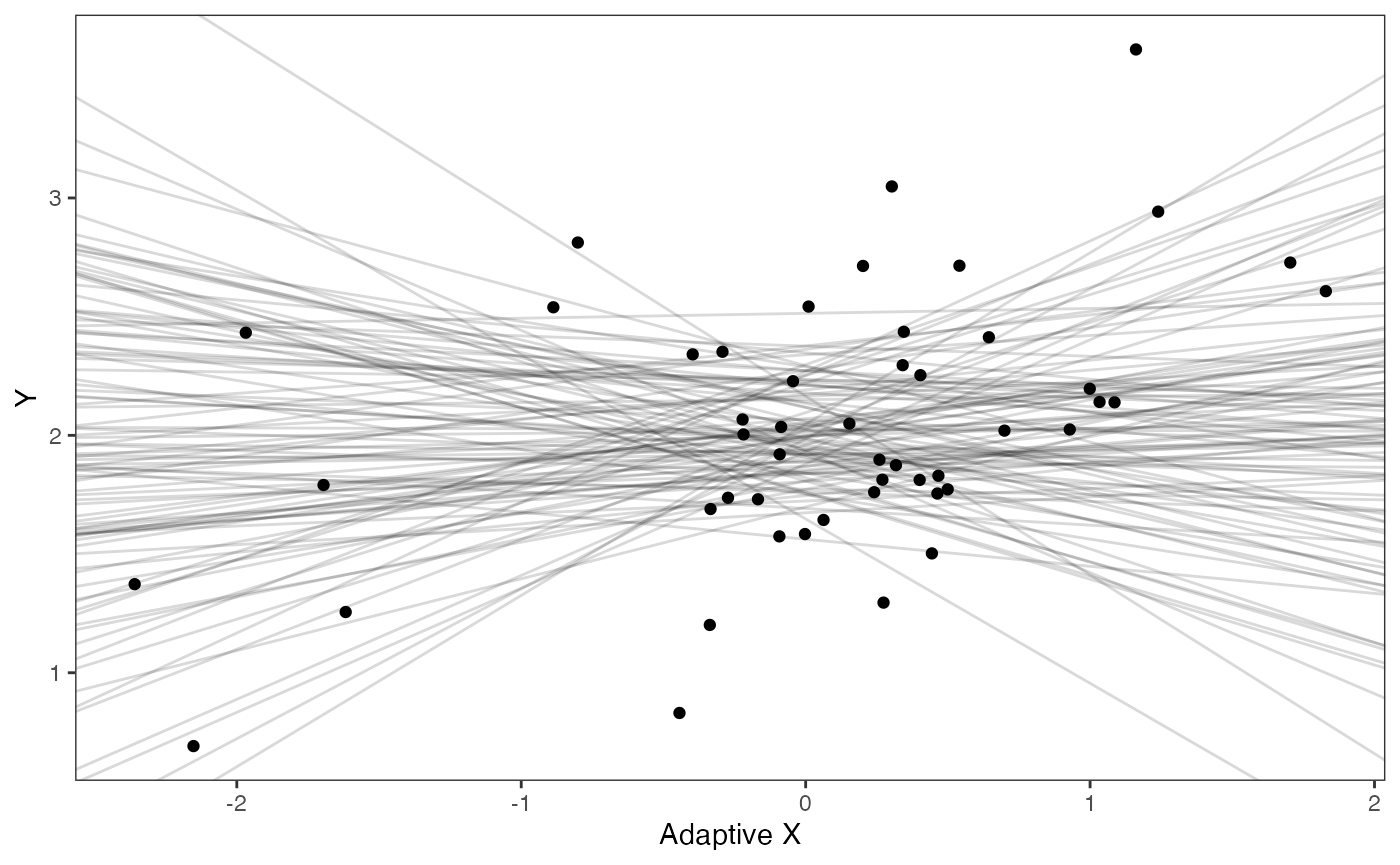
We will use the helper function blouch.direct.adapt.prep to setup the dat file for Stan. Here the names of the direct effect and adaptive columns are Xd, and Xa and their associated errors, with Z_direct and Z_adaptive the number of direct effect and adaptive traits, respectively.
############################################################################################################
#Test Blouch prep code - Direct effect + Adaptive Model
dat<-blouch.direct.adapt.prep(trdata,"Y_with_error","Y_error",c("Xd","Xa"),c("Xd_error","Xa_error"),Z_direct=1,Z_adaptive=1,hl.prior,vy.prior,optima.prior,beta.prior)Priors are set as above, and the blouchOU_direct_adapt model is run here.
fit.direct.adapt<- rstan::sampling(object = blouch:::stanmodels$blouchOU_direct_adapt,data = dat,chains = 2, cores=2,iter =2000)
#> Found more than one class "stanfit" in cache; using the first, from namespace 'rstan'
#> Also defined by 'rethinking'
#> Found more than one class "stanfit" in cache; using the first, from namespace 'rstan'
#> Also defined by 'rethinking'Here the results include, in order, the direct effect regression, the optimal regression, and finally beta_e, the evolutionary regression, following Hansen et al. (2008)
print(fit.direct.adapt,pars = c("hl","vy","optima","beta","beta_e"))
#> Inference for Stan model: blouchOU_direct_adapt.
#> 2 chains, each with iter=2000; warmup=1000; thin=1;
#> post-warmup draws per chain=1000, total post-warmup draws=2000.
#>
#> mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
#> hl 0.10 0 0.06 0.03 0.06 0.08 0.11 0.24 1197 1
#> vy 0.01 0 0.00 0.00 0.01 0.01 0.01 0.02 2555 1
#> optima 1.99 0 0.03 1.93 1.97 1.99 2.01 2.05 2922 1
#> beta[1] 0.35 0 0.01 0.33 0.34 0.35 0.35 0.36 3292 1
#> beta[2] 0.28 0 0.03 0.23 0.26 0.27 0.30 0.37 1629 1
#> beta_e[1] 0.24 0 0.02 0.20 0.23 0.24 0.25 0.28 2032 1
#>
#> Samples were drawn using NUTS(diag_e) at Sat Oct 18 11:57:06 2025.
#> For each parameter, n_eff is a crude measure of effective sample size,
#> and Rhat is the potential scale reduction factor on split chains (at
#> convergence, Rhat=1).
post<-rstan::extract(fit.direct.adapt)Now lets look at the prior vs. posterior plots for the parameters Half-life plot
hl.post<-data.frame(post$hl)
names(hl.post)<-"post.hl.sims"
hl.plot<-ggplot2::ggplot()+
ggplot2::geom_density(ggplot2::aes(prior.hl.sims,fill="prior.hl.sims"),alpha=0.2,data=hl.sims)+
ggplot2::geom_density(ggplot2::aes(post.hl.sims,fill="post.hl.sims"),alpha=0.2,data=hl.post)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#labs(title="Prior vs. Posterior Distribution ",x="Half-life", y = "Density")+
ggplot2::labs(title="",x="Half-life", y = "Density")+
#scale_fill_manual(labels=c("Posterior","Prior"))+
ggplot2::geom_vline(xintercept=c(hl),linetype=2)+
ggsci::scale_fill_npg(name="",labels=c("Posterior","Prior"))
hl.plot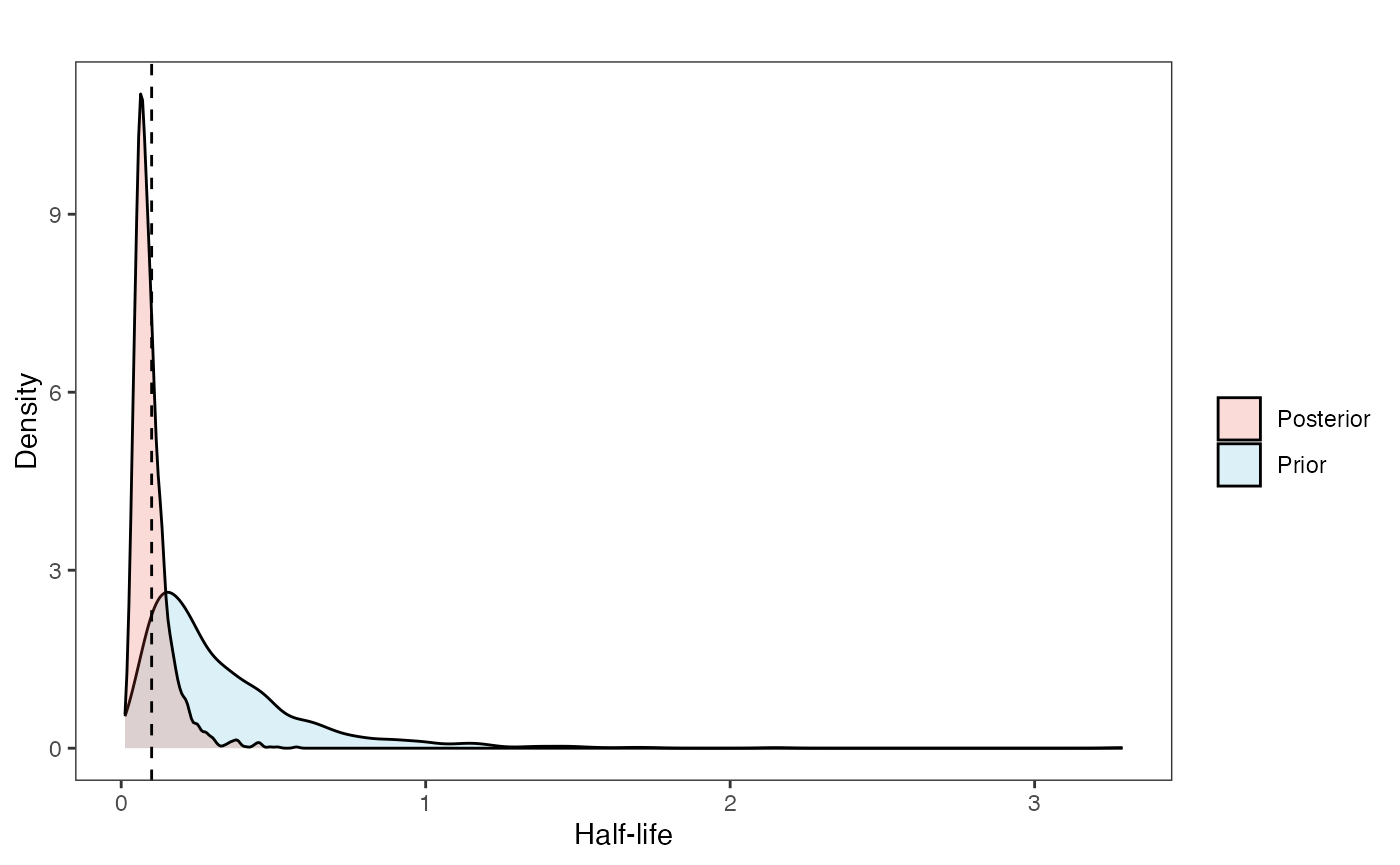
Vy Prior vs. posterior plot
vy.post<-data.frame(post$vy)
names(vy.post)<-"post.vy.sims"
vy.plot<-ggplot2::ggplot()+
ggplot2::geom_density(ggplot2::aes(prior.vy.sims,fill="prior.vy.sims"),alpha=0.2,data=vy.sims)+
ggplot2::geom_density(ggplot2::aes(post.vy.sims,fill="post.vy.sims"),alpha=0.2,data=vy.post)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#labs(title="Prior vs. Posterior Distribution ",x="vy", y = "Density")+
ggplot2::labs(title="",x="vy", y = "Density")+
ggplot2::geom_vline(xintercept=c(vy),linetype=2)+
#scale_fill_manual(labels=c("Posterior","Prior"))+
ggsci::scale_fill_npg(name="",labels=c("Posterior","Prior"))
vy.plot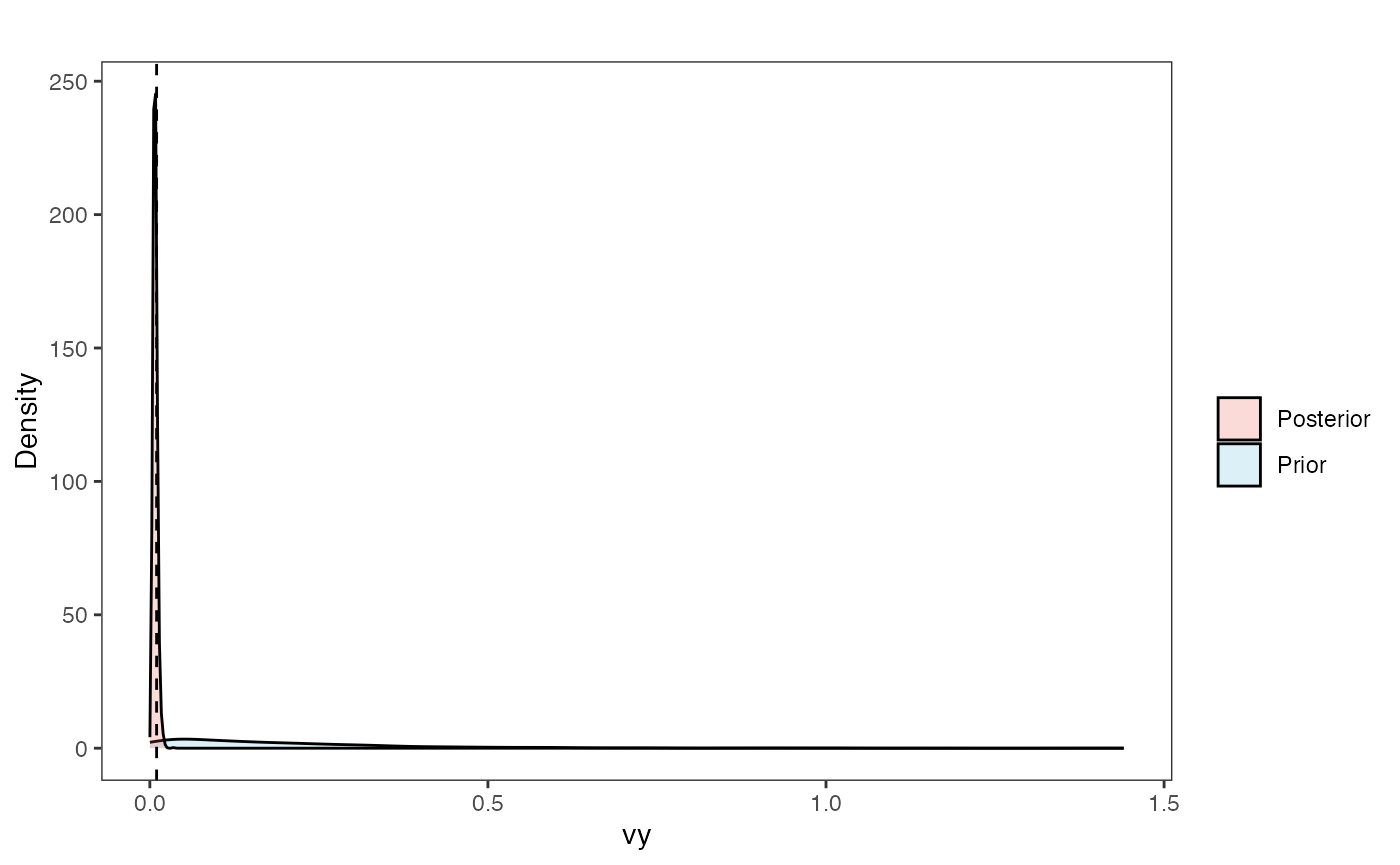
Prior versus posterior on how shared branch lengths correspond to covariance Adaptation model
a.sims<-log(2)/hl.sims;
sigma2_y.sims<-vy.sims*(2*(log(2)/hl.sims));
plot( NULL , xlim=c(0,1) , ylim=c(0,1) , xlab="Time since MRCA" , ylab="Covariance" ,cex.axis=0.75, mgp=c(1.25,0.25,0),tcl=-0.25)
for (i in 1:30){
curve(calc_adaptive_cov_plot(a.sims[i,],sigma2_y.sims[i,],beta,x) , add=TRUE , lwd=4 , col=rethinking::col.alpha(1,0.15))
}
for (i in 1:30){
curve(calc_adaptive_cov_plot(post$a[i],post$sigma2_y[i],post$beta[i],x) , add=TRUE , lwd=4 , col=rethinking::col.alpha(2,0.5))
}
par(mar=c(3,3,0.25,0.25))
covariance.plot <- recordPlot()
dev.off()
#> null device
#> 1
covariance.plotPrior vs. Posterior Plot for Regression
optima.sims<-rnorm(100,optima.prior[1],optima.prior[2])
beta.sims<-rnorm(n=100,beta.prior[1],beta.prior[2])
optima.post<-data.frame(post$optima)
names(optima.post)<-"post.optima"
beta.post<-data.frame(post$beta)
names(beta.post)<-"post.beta"
#Direct Effect Model
mu.link<-function(x.seq){optima.post+x.seq*beta.post[,1]}
x.seq <- seq(from=min(df$X.Xd), to=max(df$X.Xd) , length.out=100)
mu <- sapply(x.seq , mu.link )
mu.mean <-lapply( mu , mean )
mu.mean<-data.frame(as.numeric(mu.mean))
names(mu.mean)<-"mu.mean"
mu.CI <- lapply( mu ,rethinking:: PI , prob=0.89 )
mu.CI<-data.frame(t(data.frame(mu.CI)),x.seq)
names(mu.CI)<-c("min.5.5","max.94.5","x.seq")
df2<-data.frame(x.seq,mu.mean)
#slope.prior.plot<-ggplot(data=reg.trdata$dat,aes(y=Sim1,x=X))+
slope.diirect.plot<-ggplot2::ggplot()+
ggplot2::geom_point(data=df,ggplot2::aes(y=Y,x=X.Xd))+
ggplot2::geom_abline(intercept=optima.sims,slope=beta.sims,alpha=0.15)+
ggplot2::geom_abline(intercept=optima,slope=beta[1],alpha=0.5,linetype=2)+
ggplot2::geom_line(data=df2,ggplot2::aes(x=x.seq,y=mu.mean),linetype=1)+
ggplot2::geom_ribbon(data=mu.CI,ggplot2::aes(x=x.seq,ymin=min.5.5,ymax=max.94.5),linetype=2,alpha=0.25)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#ggtitle("Prior vs. Posterior for Intercept and Slope")+
ggplot2::ylab("Y") + ggplot2::xlab("Direct Effect X")+
ggsci::scale_color_npg()
slope.diirect.plot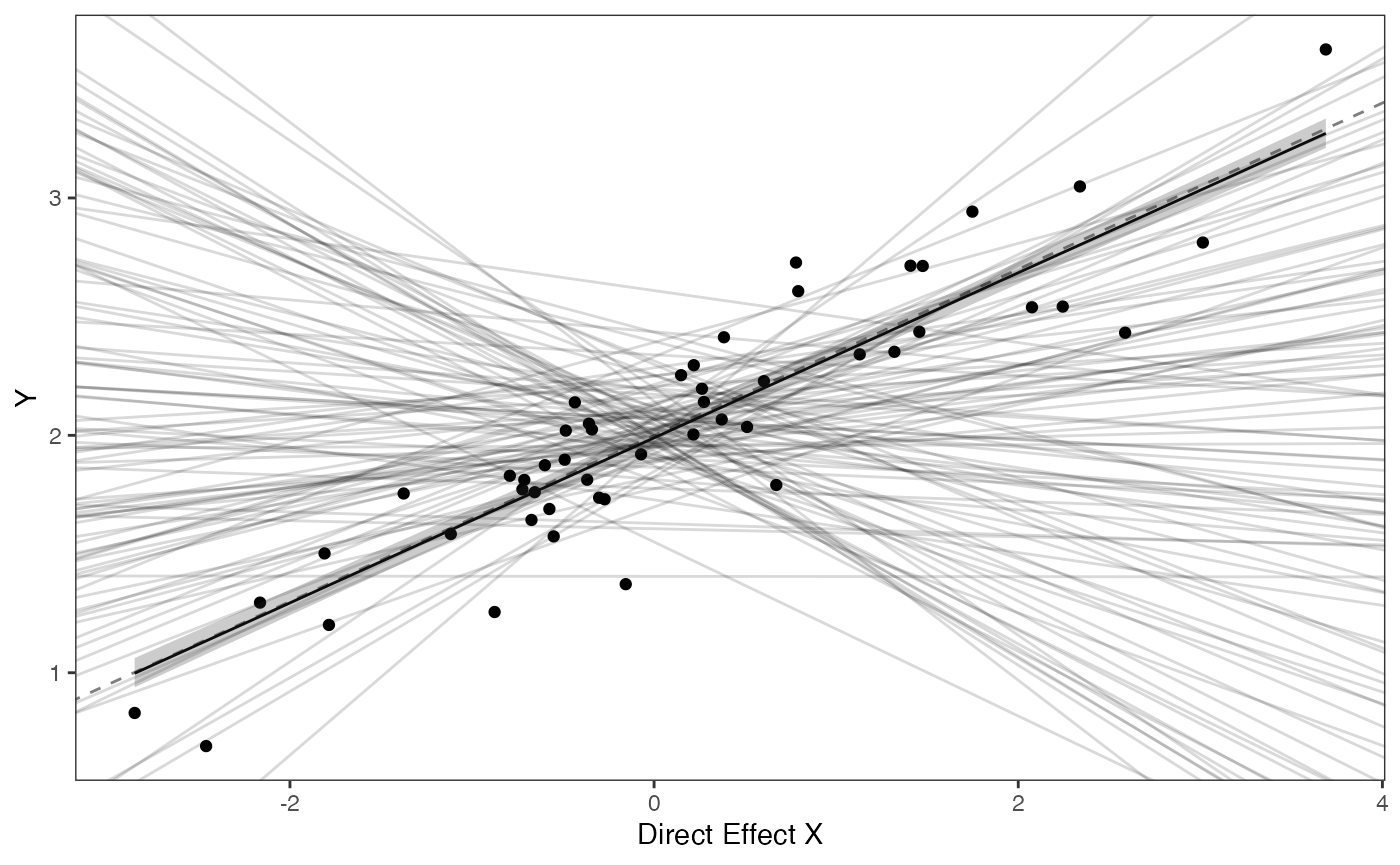
#Adaptation Model
mu.link<-function(x.seq){optima.post+x.seq*beta.post[,2]}
x.seq <- seq(from=min(df$X.Xa), to=max(df$X.Xa) , length.out=100)
mu <- sapply(x.seq , mu.link )
mu.mean <-lapply( mu , mean )
mu.mean<-data.frame(as.numeric(mu.mean))
names(mu.mean)<-"mu.mean"
mu.CI <- lapply( mu ,rethinking:: PI , prob=0.89 )
mu.CI<-data.frame(t(data.frame(mu.CI)),x.seq)
names(mu.CI)<-c("min.5.5","max.94.5","x.seq")
df2<-data.frame(x.seq,mu.mean)
#slope.prior.plot<-ggplot(data=reg.trdata$dat,aes(y=Sim1,x=X))+
slope.adapt.plot<-ggplot2::ggplot()+
ggplot2::geom_point(data=df,ggplot2::aes(y=Y,x=X.Xa))+
ggplot2::geom_abline(intercept=optima.sims,slope=beta.sims,alpha=0.15)+
ggplot2::geom_abline(intercept=optima,slope=beta[2],alpha=0.5,linetype=2)+
ggplot2::geom_line(data=df2,ggplot2::aes(x=x.seq,y=mu.mean),linetype=1)+
ggplot2::geom_ribbon(data=mu.CI,ggplot2::aes(x=x.seq,ymin=min.5.5,ymax=max.94.5),linetype=2,alpha=0.25)+
ggplot2::theme_bw()+
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank())+
#ggtitle("Prior vs. Posterior for Intercept and Slope")+
ggplot2::ylab("Y") + ggplot2::xlab("Adaptive X")+
ggsci::scale_color_npg()
slope.adapt.plot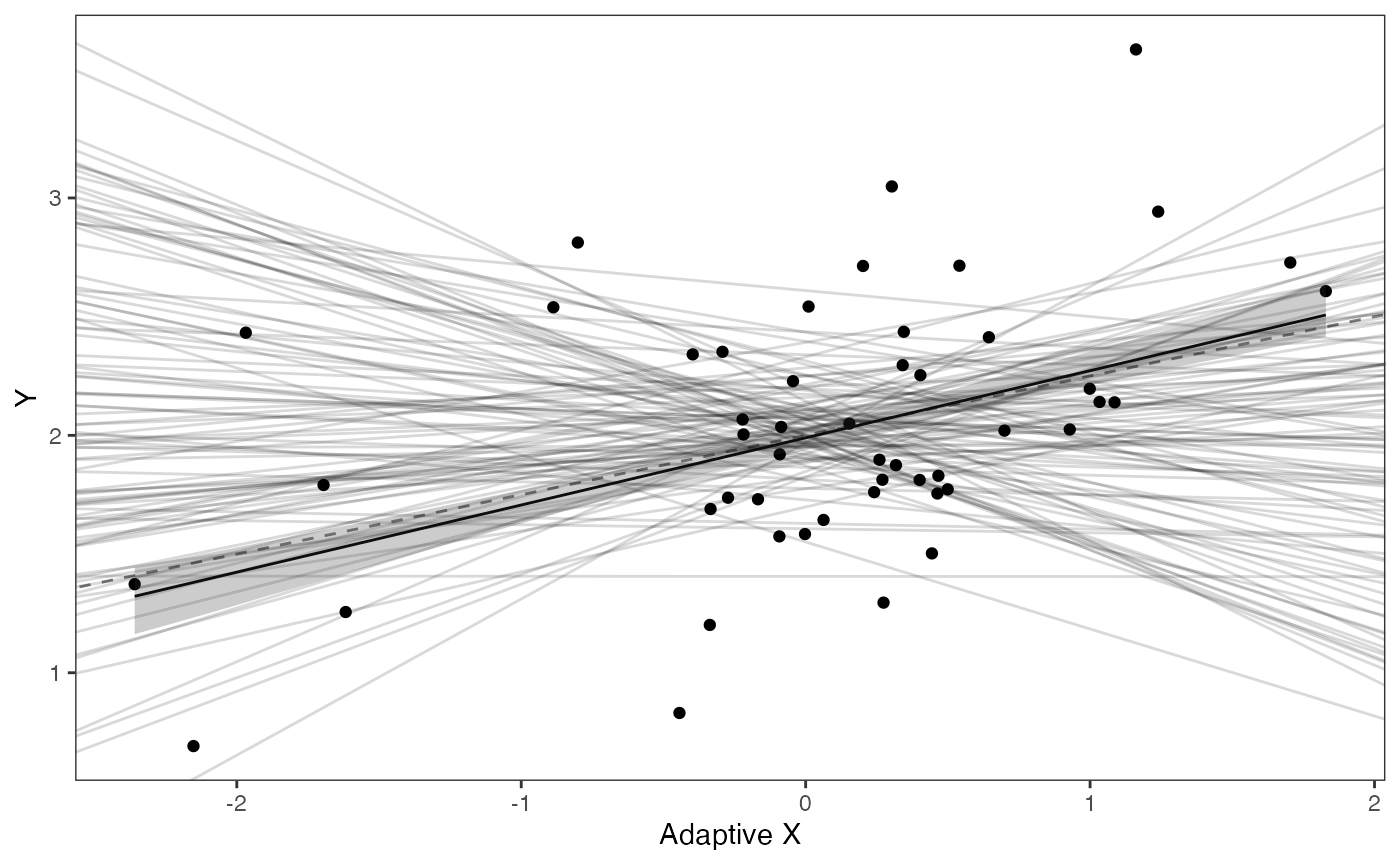
References
Grabowski M., Voje K.L., Hansen T.F. 2016. Evolutionary modeling and correcting for observation error support a 3/5 brain-body allometry for primates. J. Hum. Evol. 94:106–116.
Grabowski M., Kopperud B.T., Tsuboi M., Hansen T.F. 2023. Both Diet and Sociality Affect Primate Brain-Size Evolution. Systematic Biology.:syac075.
Hansen T.F., Bartoszek K. 2012. Interpreting the evolutionary regression: the interplay between observational and biological errors in phylogenetic comparative studies. Syst Biol. 61:413–425.
McElreath R. 2020. Statistical rethinking: A Bayesian course with examples in R and Stan. CRC press.
Revell L.J. 2011. phytools: an R package for phylogenetic comparative biology (and other things). Methods Ecol. Evol. 3:217–223.
Uyeda J.C., Harmon L.J. 2014. A Novel Bayesian Method for Inferring and Interpreting the Dynamics of Adaptive Landscapes from Phylogenetic Comparative Data. Systematic Biology. 63:902–918.